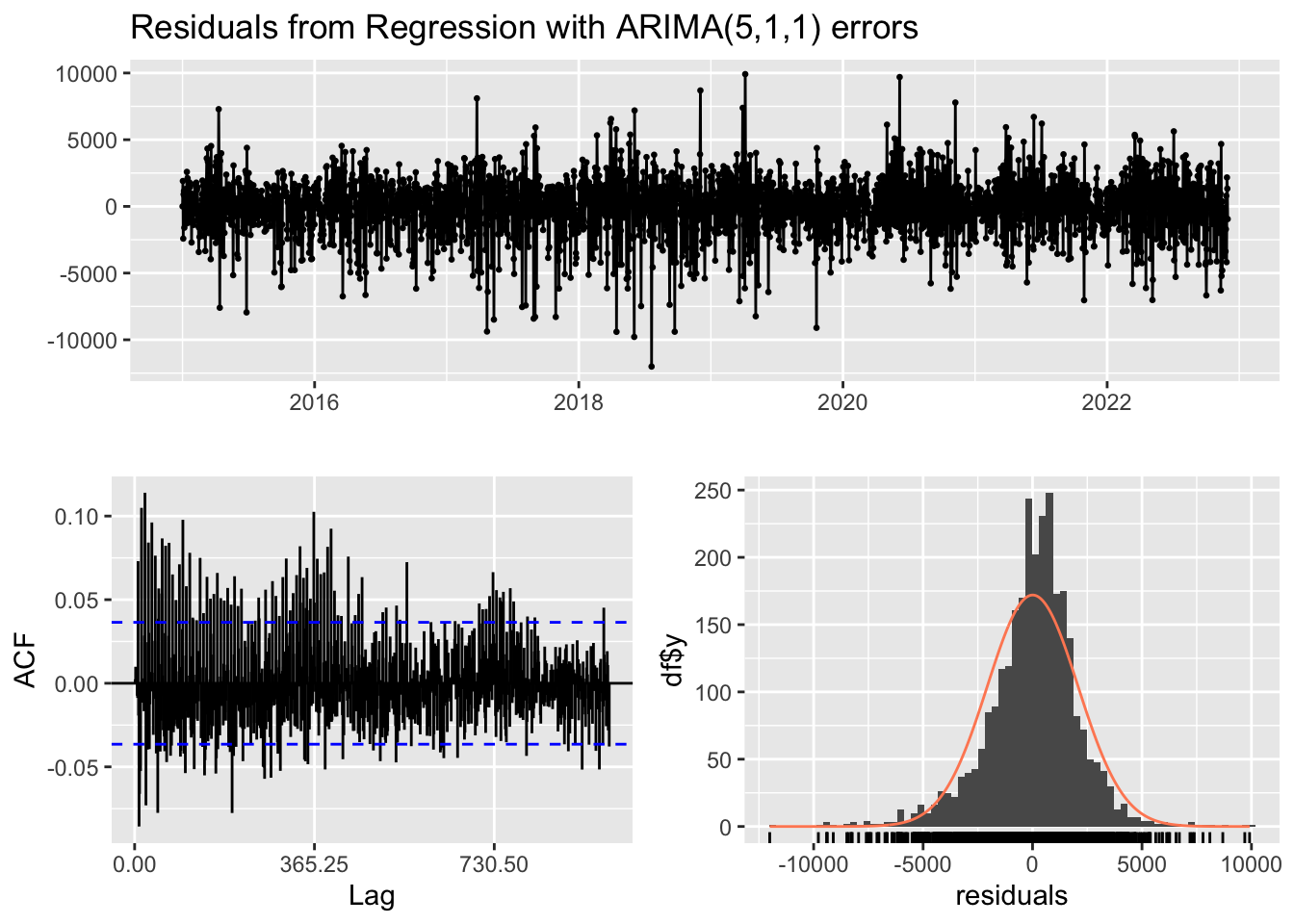
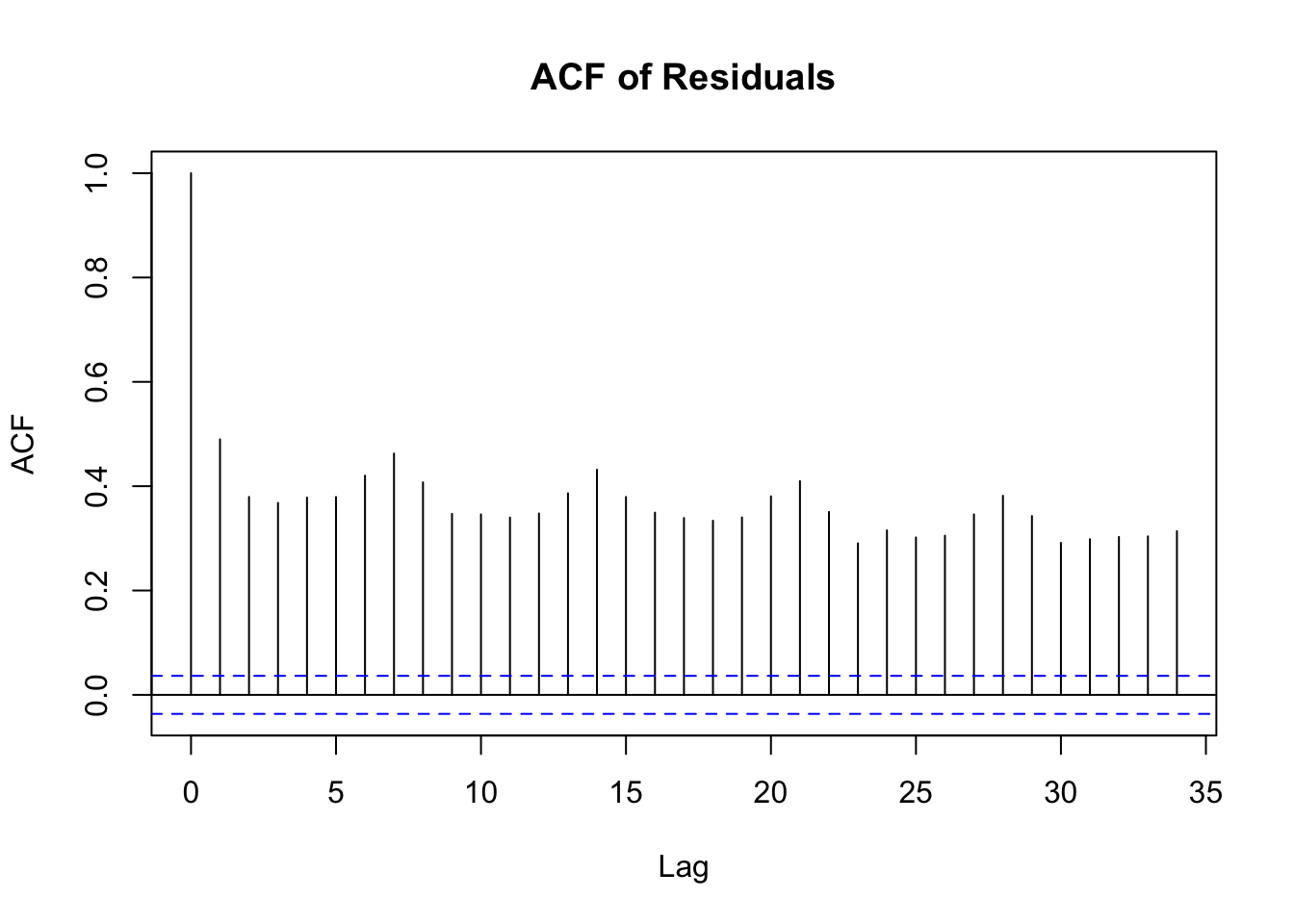
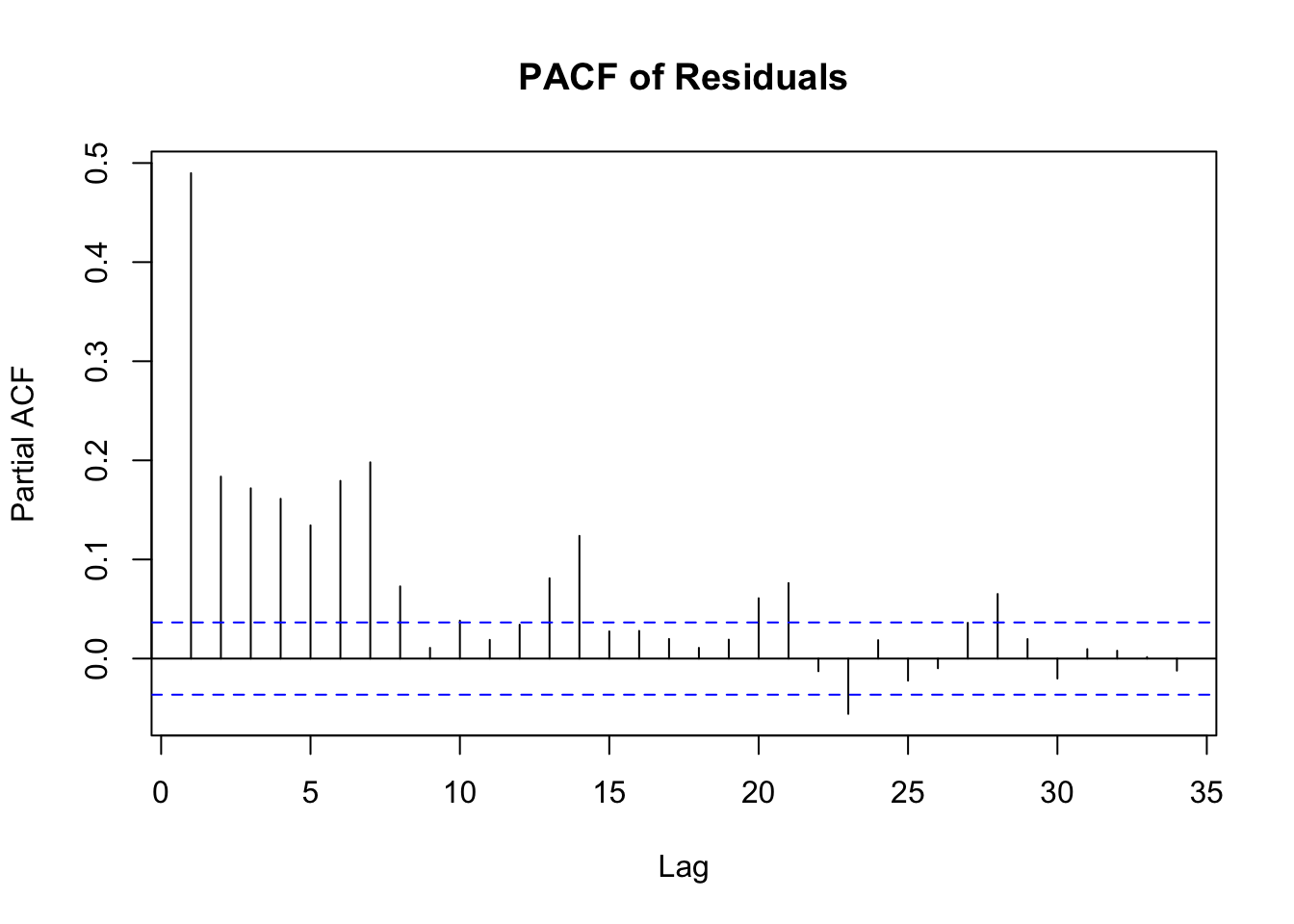
Transportation demand forecasting has been thoroughly covered in the literature. In (Banerjee, Morton, and Akartunalı 2020) the authors perform a systematic review of forecasting techniques used in scheduled passenger transportation. They found papers forecasting passenger demand for transportation primarily used the following transportation methods:
Papers most commonly focused on Airport demand, followed by Railway and Bus demand. The authors found that for short term forecasting: Pickup Models, ETS, and ARIMA models were most commonly used. In long term forecasting ARIMA and Neural networks were commonly successful in modeling.
Many of the time series forecasting models use historical demand and economic data to forecast future demand. In AI models, much more data is needed, however results can often be better. Finally, in mixed models sometimes papers use expert judgement to make adjustments to forecasts by hand that would not be done by only the model.
SARIMAX Model with Capital Bikeshare and Weather Data
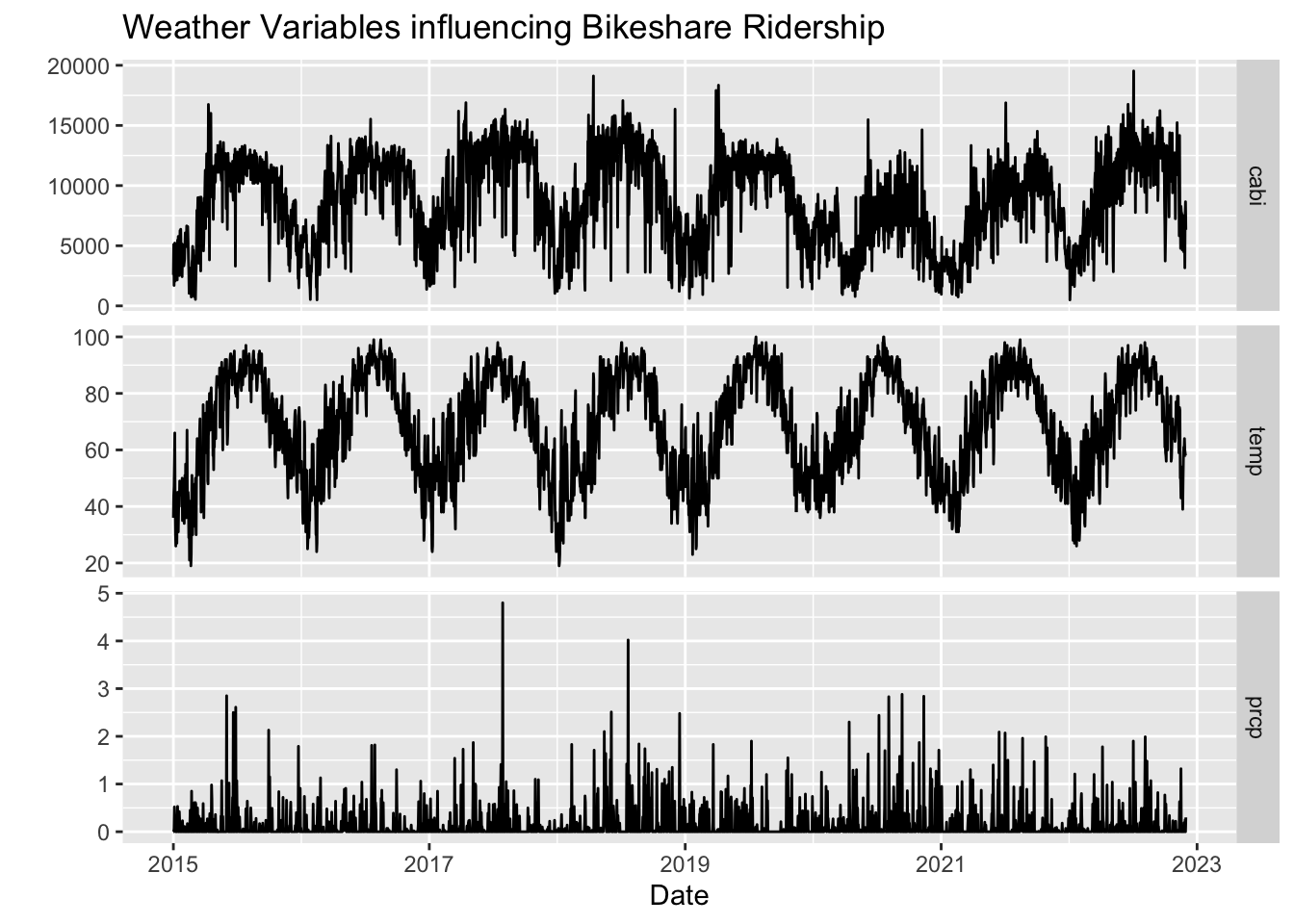
In this section daily capital bikeshare ridership will be modeled using both daily high temperature data and daily precipitation data. Daily bike ridership are likely highly dependent on these two variables because people are more likely to bike when the weather is dry and warm. Therefore, it makes sense to use these two time series as predictors of daily bike ridership.
Code
# combine time series into 1df =data.frame(date = cabi$date, cabi = cabi_time, temp = noaa_temp, prcp = noaa_prcp )df_ts =ts(df, start =2015, frequency =365.25)# plot time seriesautoplot(df_ts[,c(2:4)], facets =TRUE)+xlab("Date")+ylab("")+ggtitle("Weather Variables influencing Bikeshare Ridership")
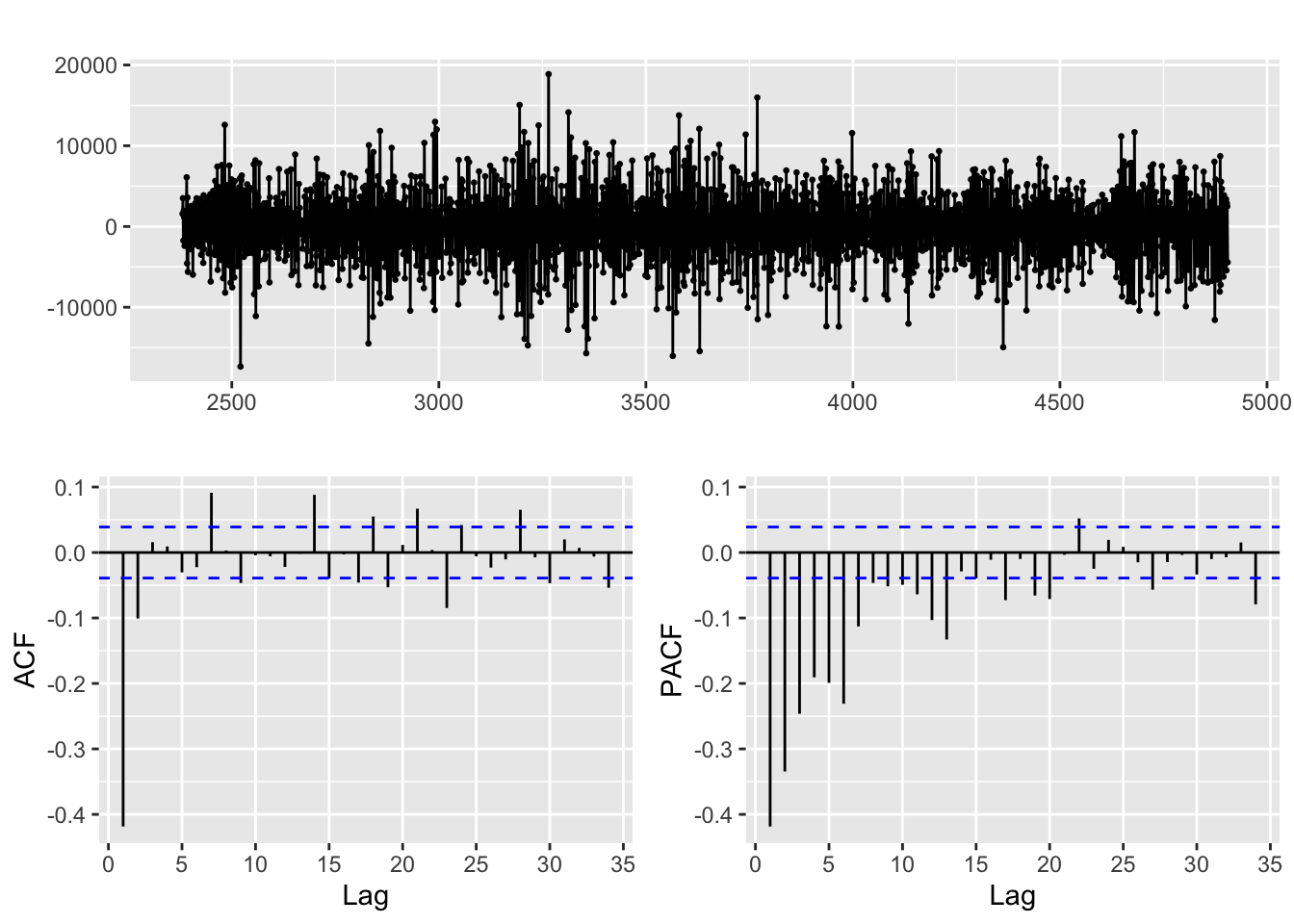
cv_2 <-function(x, h){forecast(Arima(x, order=c(0,1,1), seasonal =c(0,1,0)), h=h)}e2 =tsCV(res,cv_2, h =1)paste("RMSE 1 Step Ahead Manual Fit (0,1,1,0,1,0):", round(sqrt(mean(e2^2, na.rm =T)),1))
[1] "RMSE 1 Step Ahead Manual Fit (0,1,1,0,1,0): 2244.6"
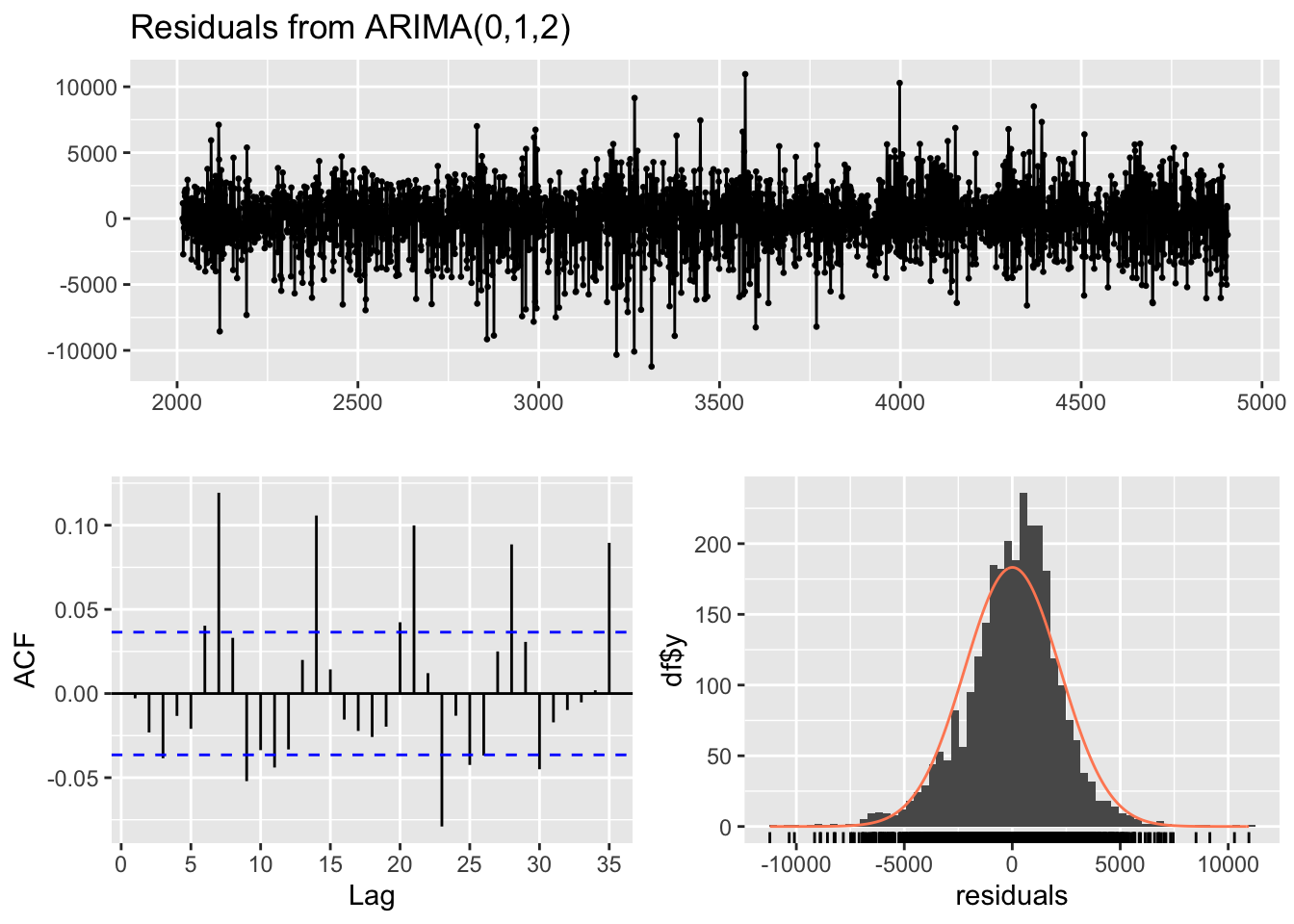
Fitting With Arima Model
Code
fit =Arima(df_ts[,"cabi"], order =c(0,1,2), seasonal =c(0,1,0), xreg = xreg)summary(fit)
Series: df_ts[, "cabi"]
Regression with ARIMA(0,1,2)(0,1,0)[365] errors
Coefficients:
ma1 ma2 temp prcp
-0.7112 -0.1869 39.8078 -359.8156
s.e. 0.0230 0.0224 5.7249 123.3157
sigma^2 = 8161143: log likelihood = -23677.58
AIC=47365.17 AICc=47365.19 BIC=47394.34
Training set error measures:
ME RMSE MAE MPE MAPE MASE
Training set -2.253237 2667.705 1861.564 -9.341714 30.24737 0.6419317
ACF1
Training set -0.0005653654
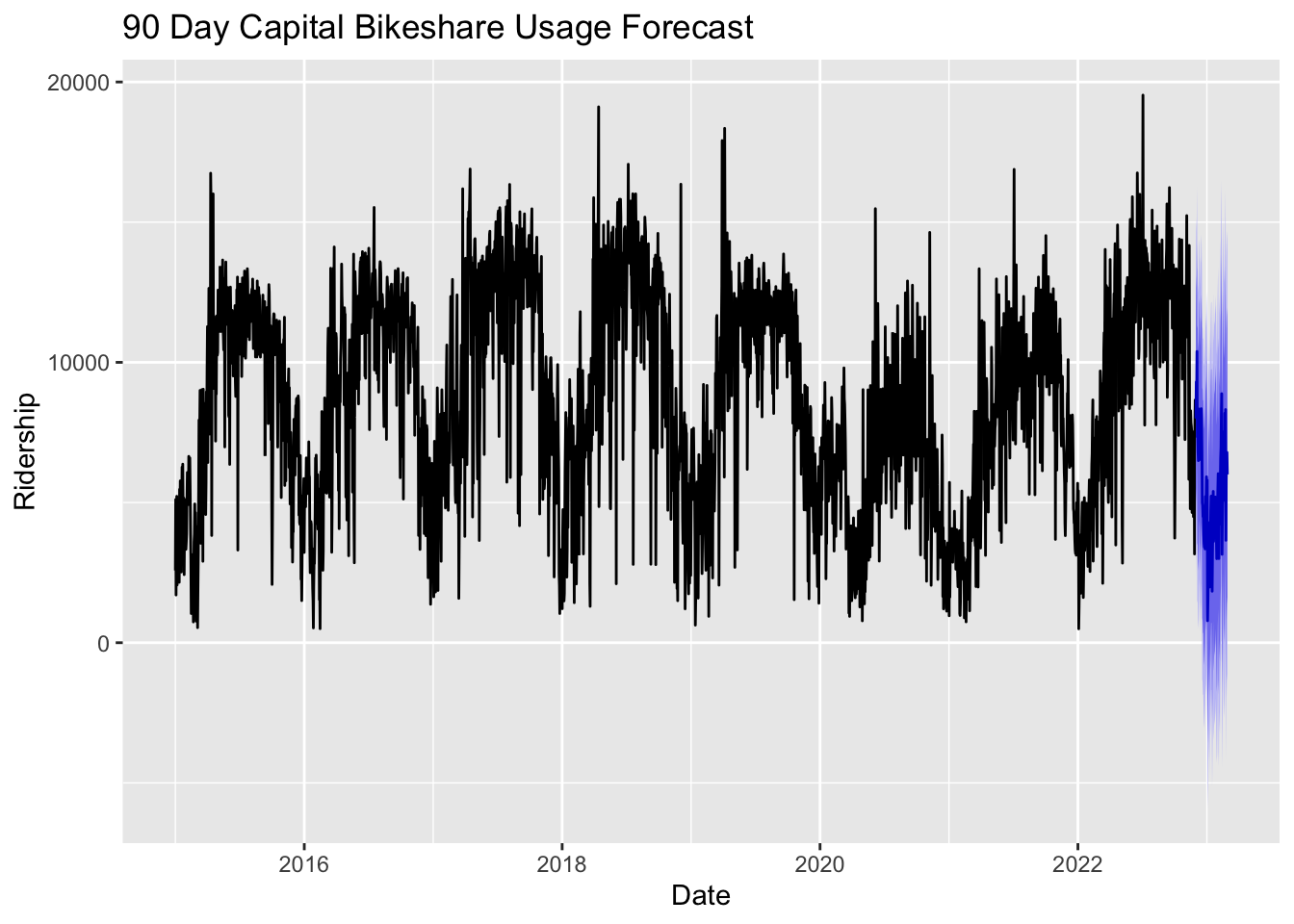
Forecasting
This is the 90 day forecast for capital bikeshare usage based on weather data. The trend is definitely what we would expect to see as it continues the seasonality of previous years and lines up with ridership we would expect to see between December and February. The confidence bands are still quite large indicating that there is still significant variation in the data.
Code
# Forecast temptemp_fit =auto.arima(noaa_temp)
Warning: The time series frequency has been rounded to support seasonal
differencing.
Code
temp_fcast =forecast(temp_fit, 90)# forecast prcpprcp_fit =auto.arima(noaa_prcp)prcp_fcast =forecast(prcp_fit, 90)# combine input variable forecastsfxreg =cbind(temp = temp_fcast$mean,prcp = prcp_fcast$mean)fcast_cabi =forecast(fit, xreg = fxreg, h =90)autoplot(fcast_cabi) +xlab("Date")+ylab("Ridership")+ggtitle("90 Day Capital Bikeshare Usage Forecast")
VAR Model with Capital Bikeshare, Metro Rail, and Metro Bus
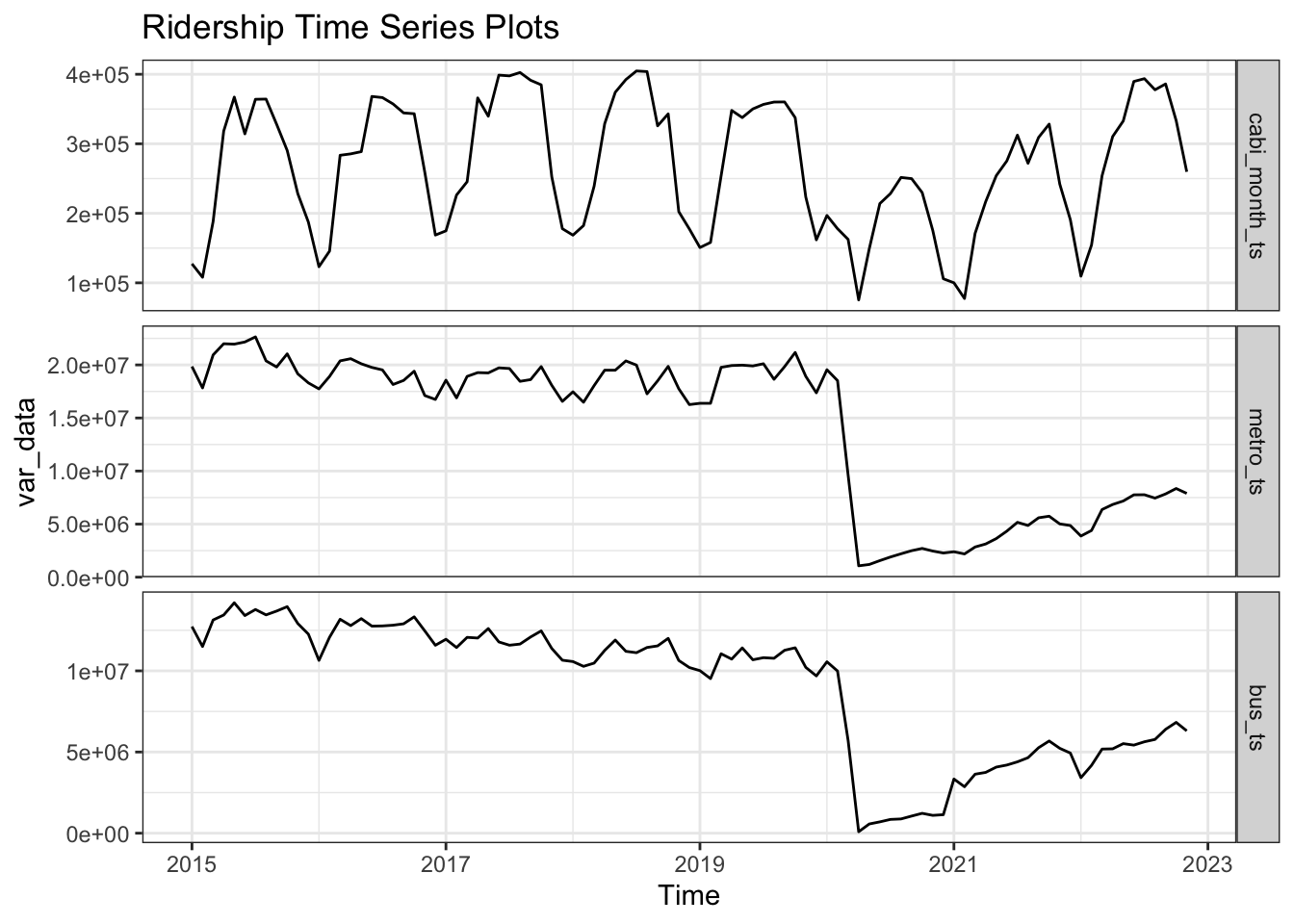
Here we will model a multivariate time series consisting of Capital Bikeshare monthly ridership, metro rail monthly time series, and metro bus monthly time series. The time period is limited between January 2015 and November 2022 to ensure there is no missing data for any of the time series. It makes sense to model these time series together because each one measures ridership of a mode of public transportation in Washington DC. It is reasonable to assume that the ridership of one mode of transportation affects ridership of other modes of transportation and that changes in trend of ridership for each mode likely change together as well.
Exploratory Analysis
Code
# Create var data by combining three timeseriesvar_data =window(ts.union(cabi_month_ts, metro_ts, bus_ts), start =2015, end =c(2022, 11))# Plot Timeseries of all 3 variablesautoplot(var_data, facets = T) +labs(title ="Ridership Time Series Plots")+theme_bw()
Code
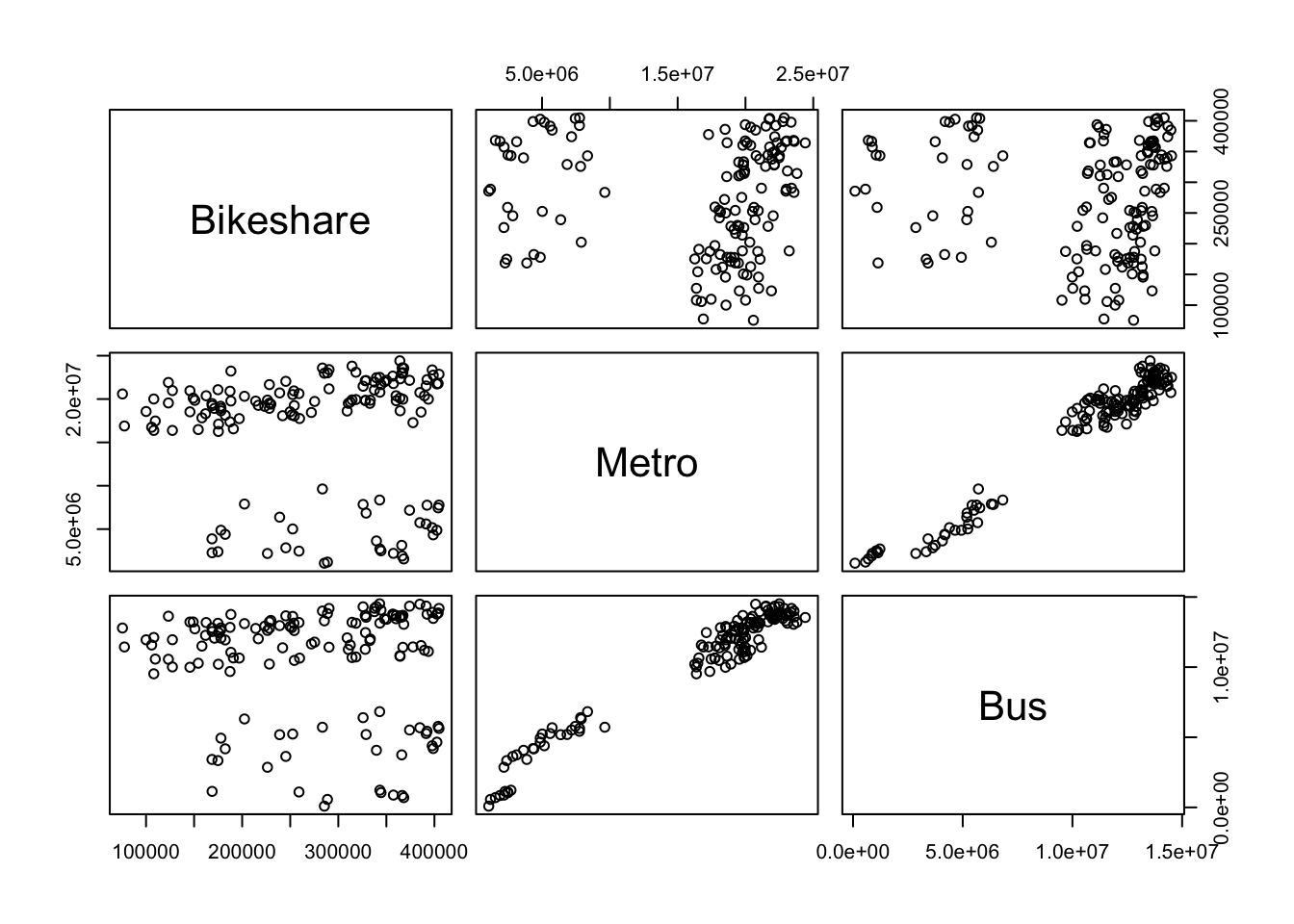
# Plot Pairspairs(cbind(Bikeshare = cabi_month$month_count, Metro = metro$Riders_Total, Bus = bus$Riders_Total))
Optimal Lag (p)
Using the VARselect function we find that the choices for p are 1,4,14.
Portmanteau Test (asymptotic)
data: Residuals of VAR object var14
Chi-squared = 91.547, df = 0, p-value < 2.2e-16
Code
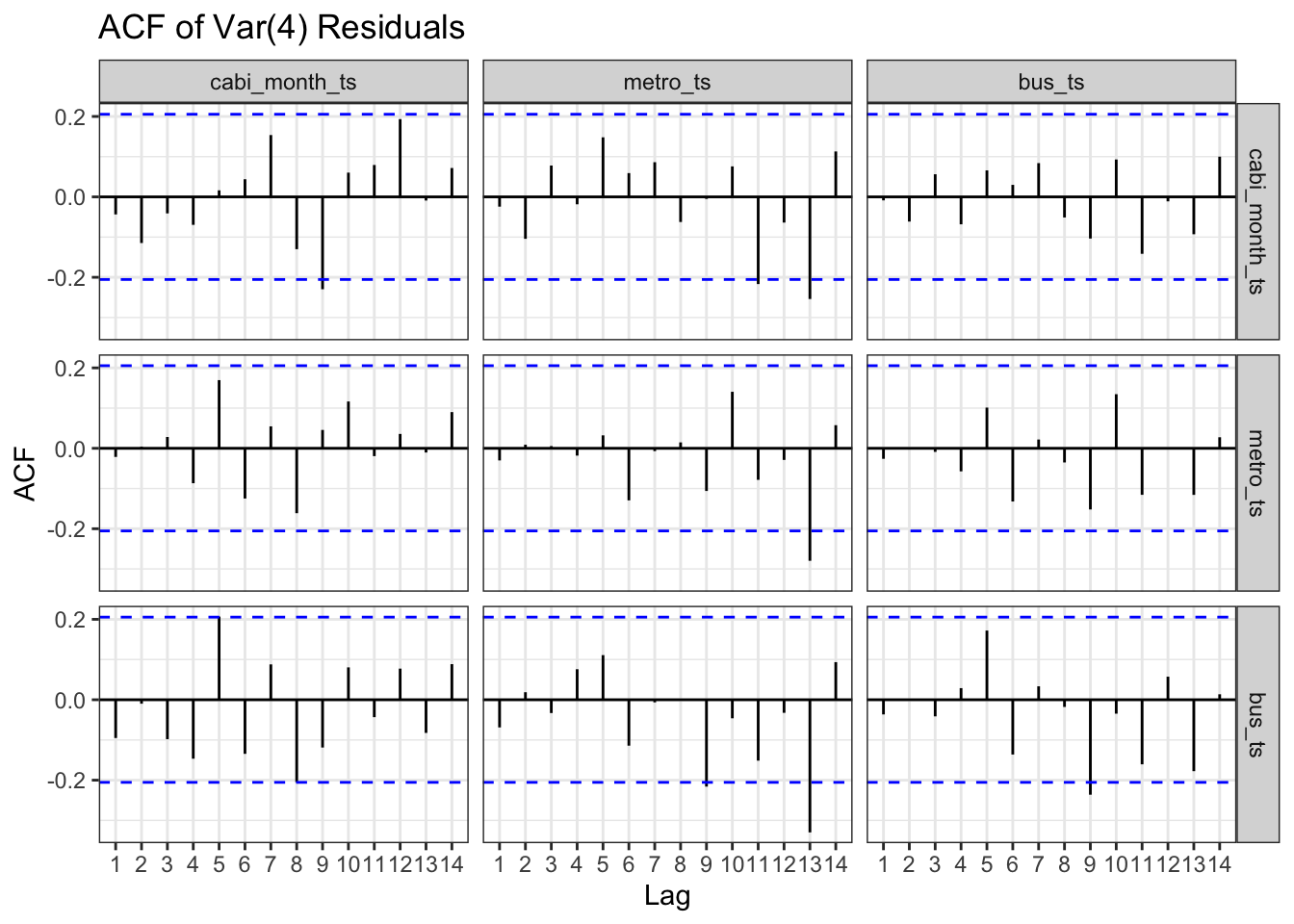
ggAcf(residuals(var4)) +ggtitle("ACF of Var(4) Residuals") +theme_bw()
Cross Validation
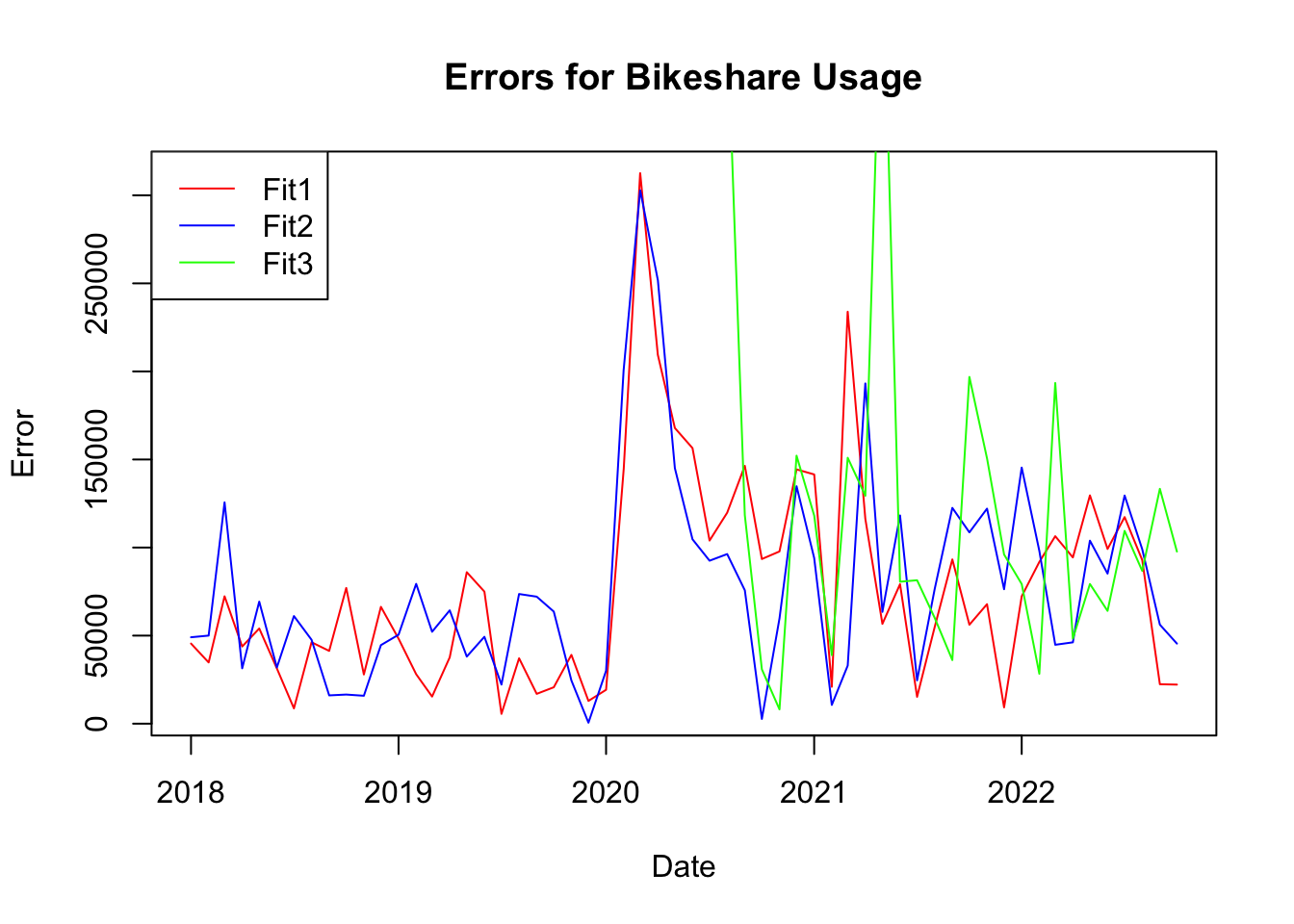
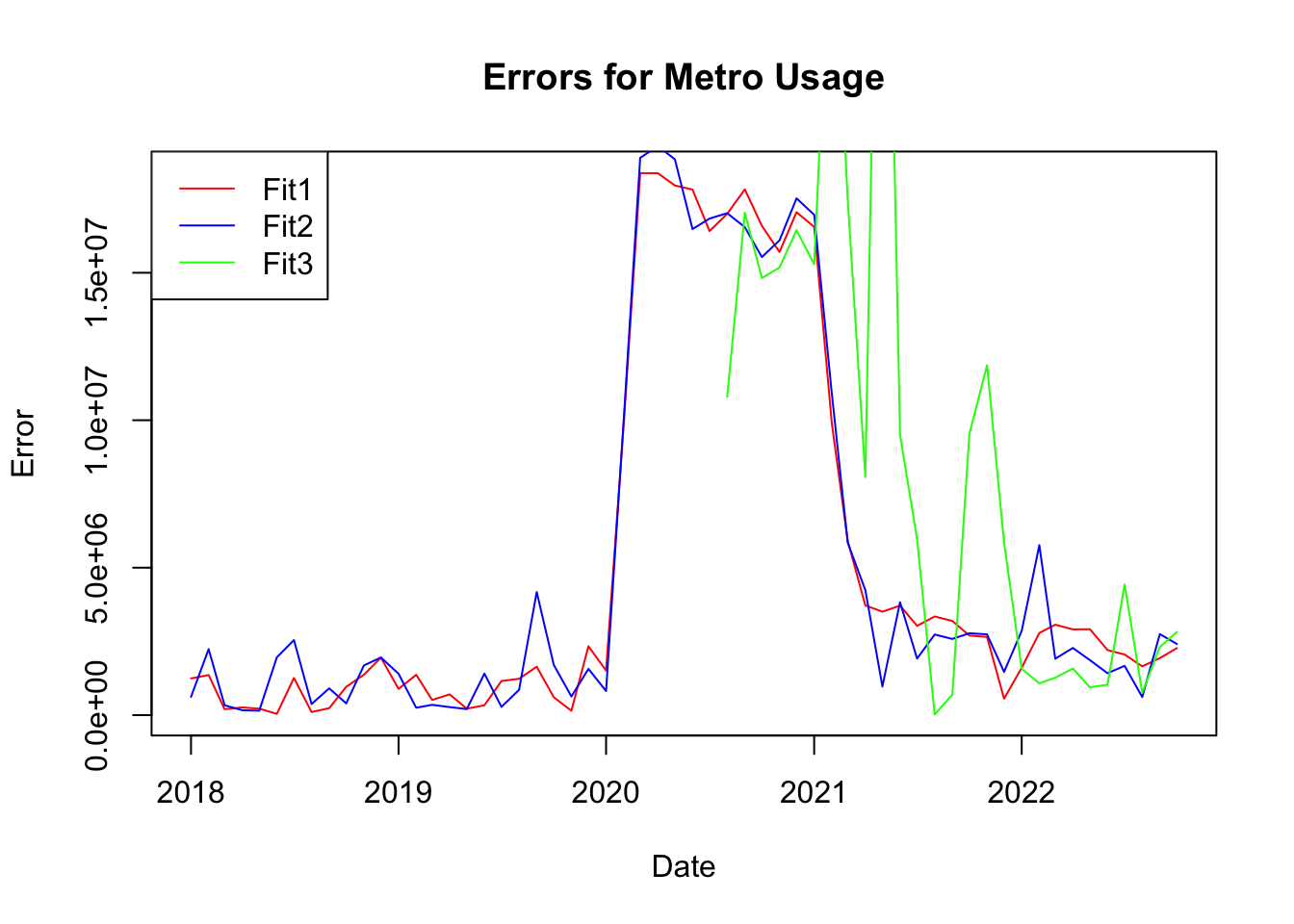
By Performing cross validation we find that models with p = 1 and p = 4 have signficantly smaller error than p = 14. Model 1 outperforms Model 2 slightly, however due to the serial correlation of model 1, we will choose model 2 (p=4) as the optimal model.
plot(errors1$date, errors1$X1, type ="l", col ="red", main ="Errors for Bikeshare Usage", xlab ="Date", ylab ="Error")lines(errors2$date, errors2$X1, type ="l", col ="blue")lines(errors3$date, errors3$X1, type ="l", col ="green")legend("topleft",legend =c("Fit1", "Fit2", "Fit3"), col =c("red", "blue", "green"), lty =1)
Code
plot(errors1$date, errors1$X2, type ="l", col ="red", main ="Errors for Metro Usage", xlab ="Date", ylab ="Error")lines(errors2$date, errors2$X2, type ="l", col ="blue")lines(errors3$date, errors3$X2, type ="l", col ="green")legend("topleft",legend =c("Fit1", "Fit2", "Fit3"), col =c("red", "blue", "green"), lty =1)
Code
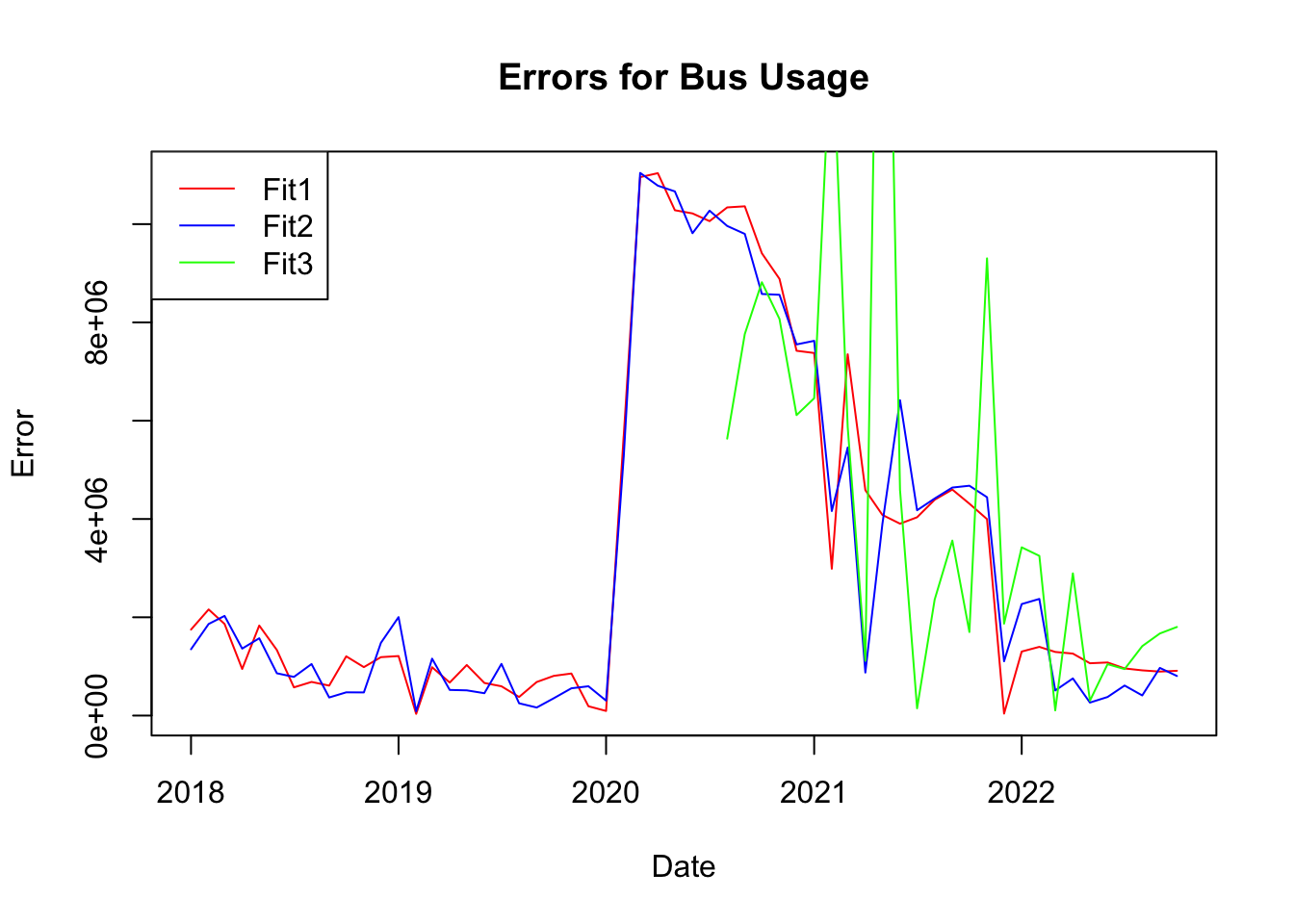
plot(errors1$date, errors1$X3, type ="l", col ="red", main ="Errors for Bus Usage", xlab ="Date", ylab ="Error")lines(errors2$date, errors2$X3, type ="l", col ="blue")lines(errors3$date, errors3$X3, type ="l", col ="green")legend("topleft",legend =c("Fit1", "Fit2", "Fit3"), col =c("red", "blue", "green"), lty =1)
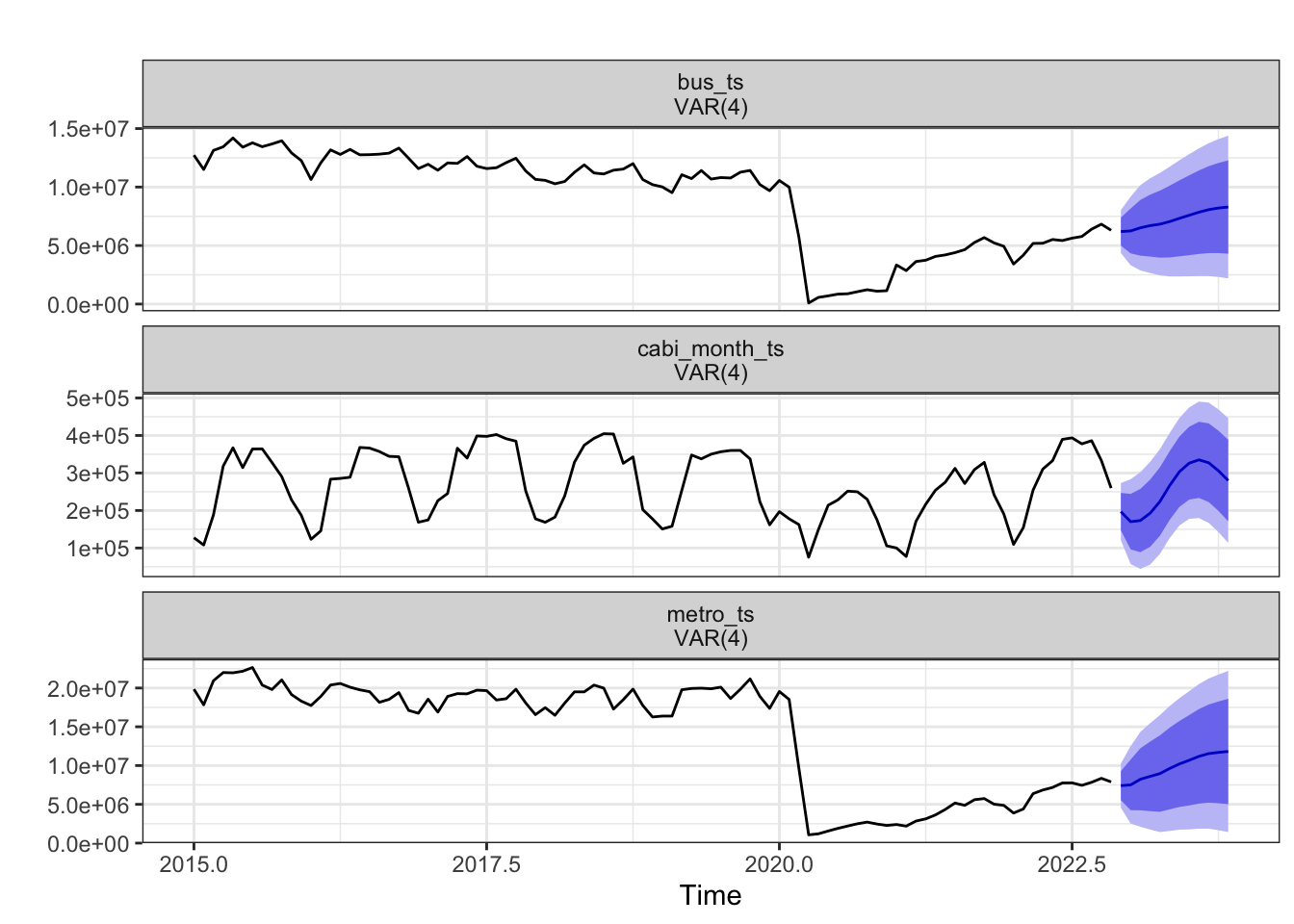
Here we plot the 1 year forecasts for each time series using the optimal var model (p=4). Both Metro Rail and Metro Bus ridership are expected to increase over the next year which makes sense because they are still recovering from the decrease in demand during the pandemic. The capital bikeshare forecast captures the seasonality of that time series and is expected to remain similar in ridership to the previous years. Seasonality is not seen in the metro rail or metro bus forecast. The confidence bands are smaller than in the previous univariate time series model as we can now explain more of the variation in the data.
Code
fit=VAR(var_data, p =4, type ="const")autoplot(forecast(fit, h =12))+theme_bw()
References
Banerjee, Nilabhra, Alec Morton, and Kerem Akartunalı. 2020. “Passenger Demand Forecasting in Scheduled Transportation.”European Journal of Operational Research 286 (3): 797–810. https://doi.org/https://doi.org/10.1016/j.ejor.2019.10.032.