In this section 3 deep learning models will be implemented on the Capital Bikeshare Daily Ridership data. The goal will remain the same as previous sections which is to correctly forecast future ridership.
Data Preparation
Train/Test Sizes
Code
# Read in Datadf = pd.read_csv("./Data/CleanData/cabi.csv")df = df.rename(columns={"date": "t", "count": "y"})df = df[["t", "y"]]X = np.array(df["y"].values.astype("float32")).reshape(df.shape[0], 1)# Parameter split_percent defines the ratio of training examplesdef get_train_test(data, split_percent=0.8): scaler = MinMaxScaler(feature_range=(0, 1)) data = scaler.fit_transform(data).flatten() n =len(data)# Point for splitting data into train and test split =int(n * split_percent) train_data = data[range(split)] test_data = data[split:]return train_data, test_data, datatrain_data, test_data, data = get_train_test(X)print("train shape:", train_data.shape)print("test shape:", test_data.shape)
train shape: (2334,)
test shape: (584,)
Train/Test Visualization
Code
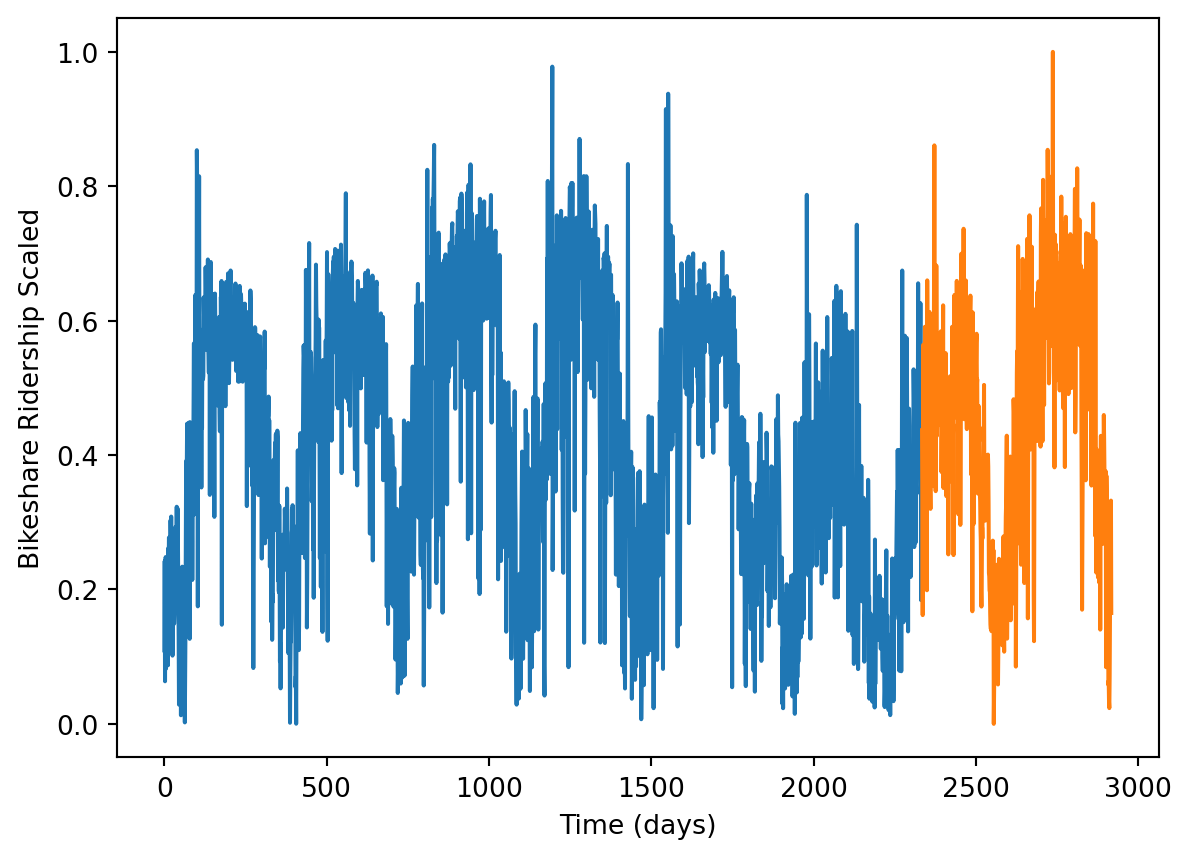
# Visualize the Training and Test Setsfig, ax = plt.subplots()ax.plot(range(0, len(train_data)), train_data, "-")ax.plot(range(len(train_data), len(X)), test_data, "-")ax.set(xlabel="Time (days)", ylabel="Bikeshare Ridership Scaled")plt.show()
Deep Learning Models
Data Preparation
This code was adapted from Professor Hickman’s Sunspot Prediction Example.
Code
# PREPARE THE INPUT X AND TARGET Ydef get_XY(dat, time_steps, plot_data_partition=False):global X_ind, X, Y_ind, Y # use for plotting later# INDICES OF TARGET ARRAY# Y_ind [ 12 24 36 48 ..]; print(np.arange(1,12,1)); exit() Y_ind = np.arange(time_steps, len(dat), time_steps)# print(Y_ind); exit() Y = dat[Y_ind]# PREPARE X rows_x =len(Y) X_ind = [*range(time_steps * rows_x)]del X_ind[::time_steps] # if time_steps=10 remove every 10th entry X = dat[X_ind]# PLOTif plot_data_partition: plt.figure(figsize=(15, 6), dpi=80) plt.plot(Y_ind, Y, "o", X_ind, X, "-") plt.show()# RESHAPE INTO KERAS FORMAT X1 = np.reshape(X, (rows_x, time_steps -1, 1))# print([*X_ind]); print(X1); print(X1.shape,Y.shape); exit()return X1, Y# PARTITION DATAp =30#testX, testY = get_XY(test_data, p)trainX, trainY = get_XY(train_data, p)
Input Array Shapes (Test/Train)
Code
# USER PARAMrecurrent_hidden_units =3epochs =200f_batch =0.2# fraction used for batch sizeoptimizer ="RMSprop"validation_split =0.2# trainY=trainY.reshape(trainY.shape[0],1)# testY=testY.reshape(testY.shape[0],1)print("Testing Array Shape:", testX.shape, testY.shape)print("Training Array Shape:", trainX.shape, trainY.shape)
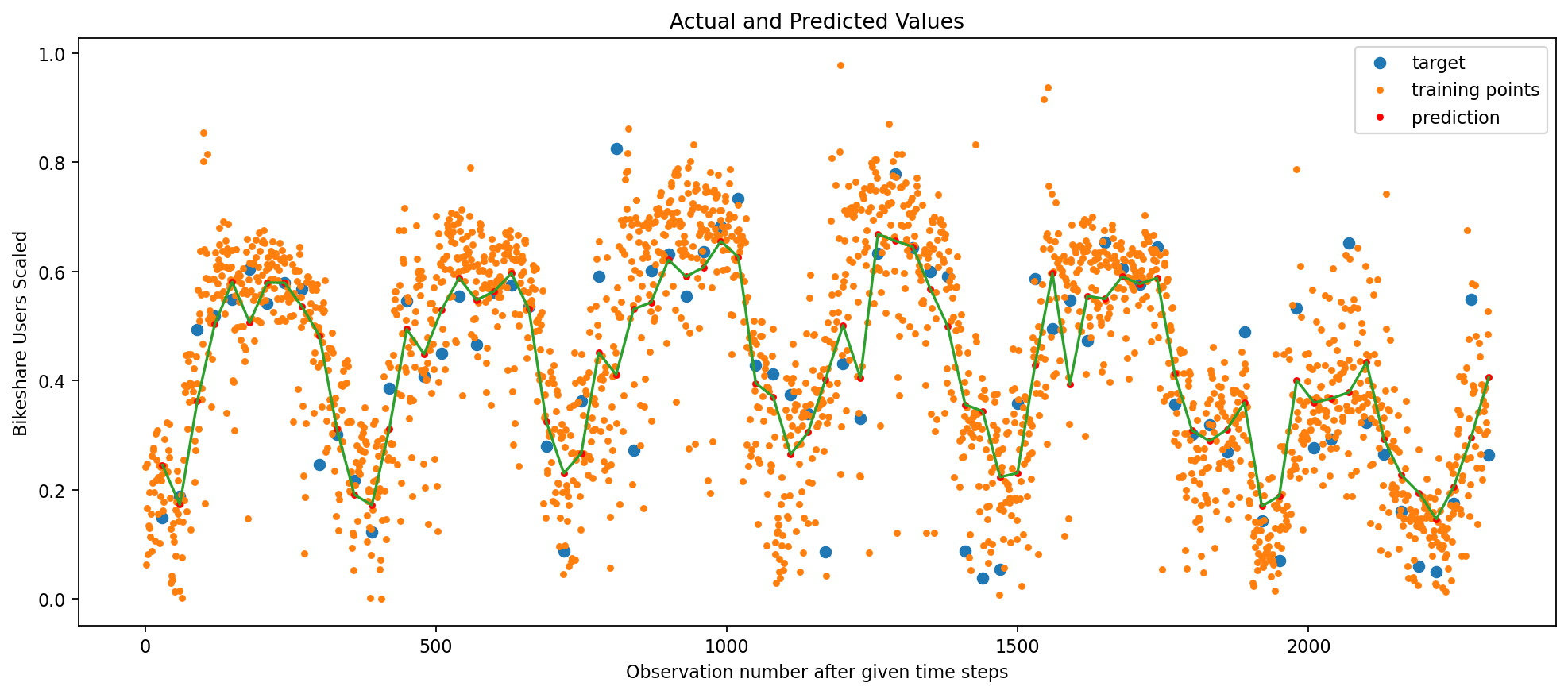
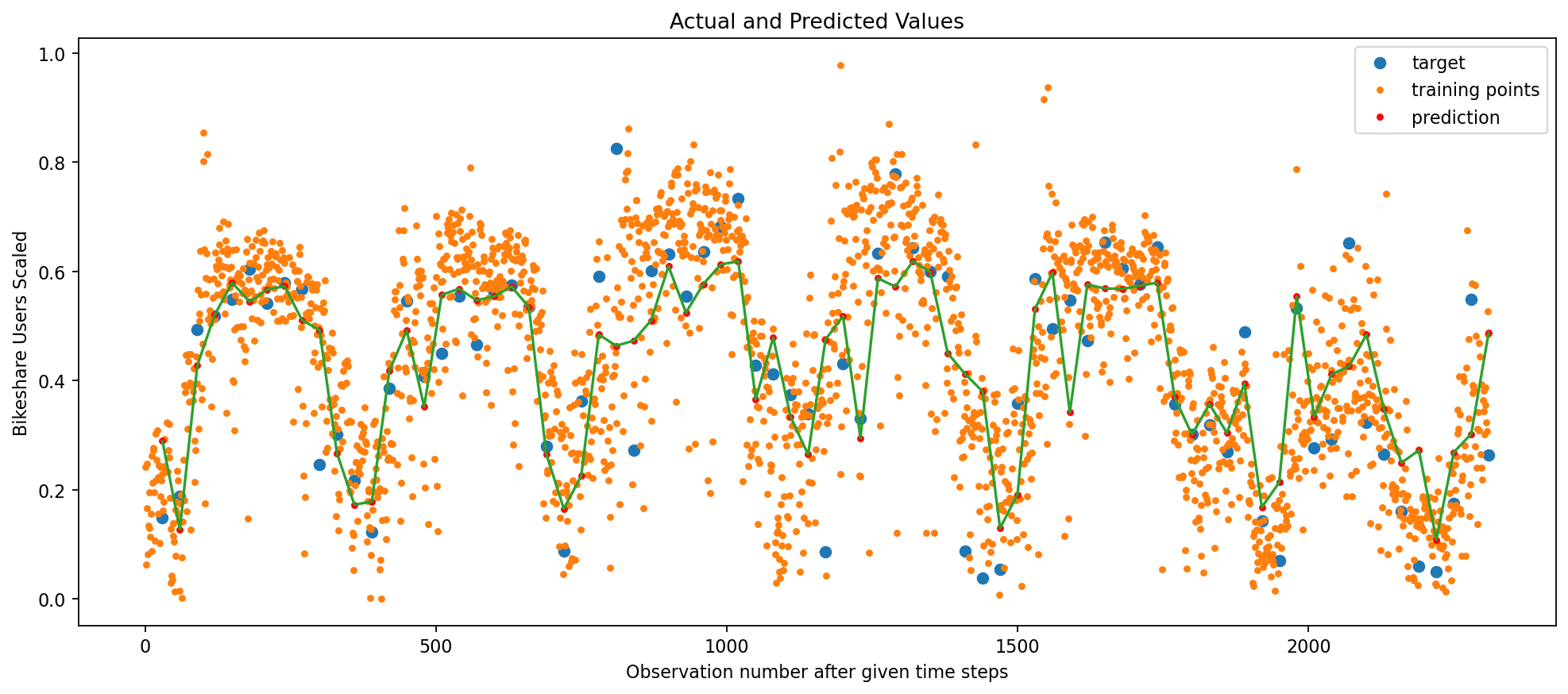
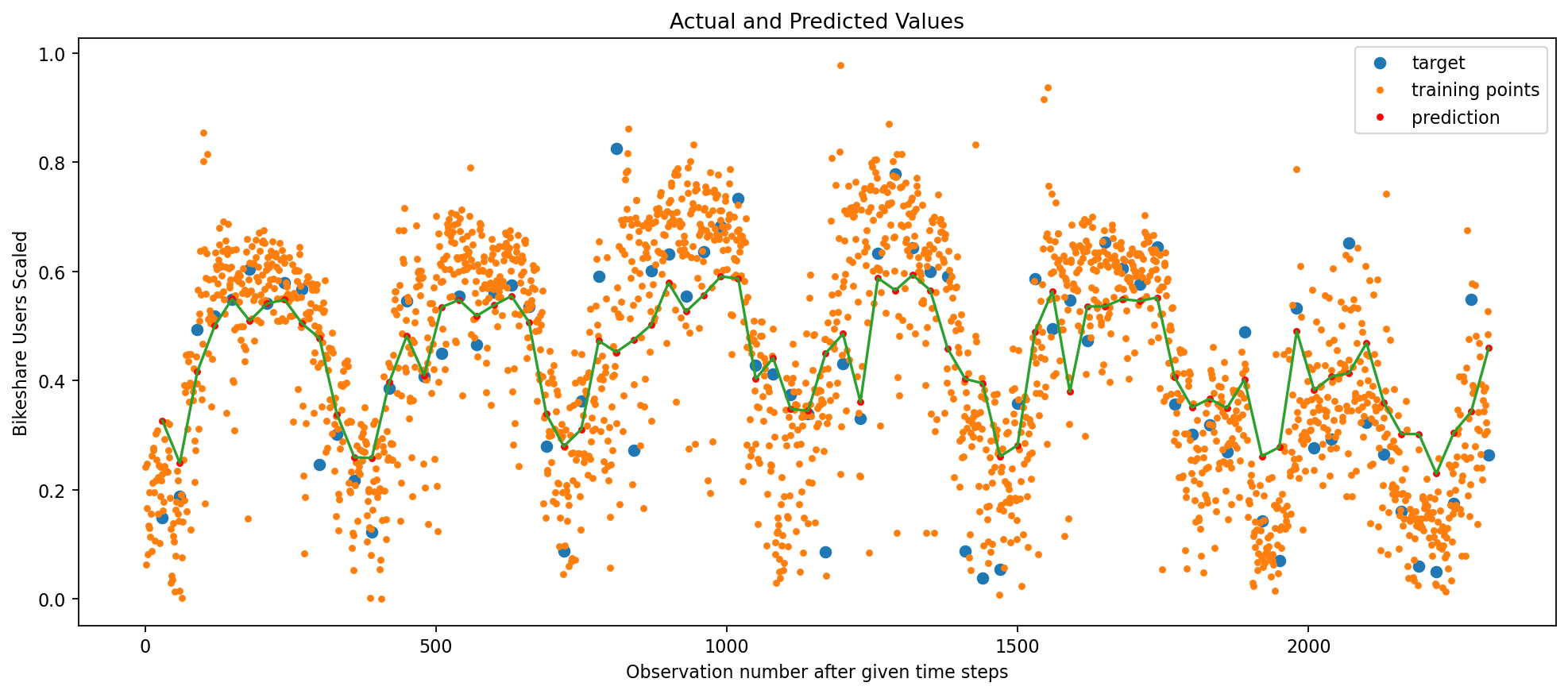
# CREATE MODELmodel = Sequential()# COMMENT/UNCOMMENT TO USE RNN, LSTM,GRUmodel.add( LSTM(# model.add(SimpleRNN(# model.add(GRU( recurrent_hidden_units, return_sequences=False, input_shape=(trainX.shape[1], trainX.shape[2]),# recurrent_dropout=0.8, recurrent_regularizer=regularizers.L2(1e-2), activation="tanh", ))# NEED TO TAKE THE OUTPUT RNN AND CONVERT TO SCALARmodel.add(Dense(units=1, activation="linear"))# COMPILE THE MODELmodel.compile(loss="MeanSquaredError", optimizer=optimizer)model.summary()# TRAIN MODELhistory = model.fit( trainX, trainY, epochs=epochs, batch_size=int(f_batch * trainX.shape[0]), validation_split=validation_split, verbose=0,)# MAKE PREDICTIONStrain_predict = model.predict(trainX).squeeze()test_predict = model.predict(testX).squeeze()print( trainX.shape, train_predict.shape, trainY.shape, testX.shape, test_predict.shape, testY.shape,)# COMPUTE RMSEprint(trainY.shape, train_predict.shape)train_rmse = np.sqrt(mean_squared_error(trainY, train_predict))test_rmse = np.sqrt(mean_squared_error(testY, test_predict))print(np.mean((trainY - train_predict) **2.0))print(np.mean((testY - test_predict) **2.0))print("Train MSE = %.5f RMSE = %.5f"% (train_rmse**2.0, train_rmse))print("Test MSE = %.5f RMSE = %.5f"% (test_rmse**2.0, test_rmse))# PLOT THE RESULTdef plot_result(trainY, testY, train_predict, test_predict): plt.figure(figsize=(15, 6), dpi=80)# ORIGINAL DATAprint(X.shape, Y.shape) plt.plot(Y_ind, Y, "o", label="target") plt.plot(X_ind, X, ".", label="training points") plt.plot(Y_ind, train_predict, "r.", label="prediction") plt.plot(Y_ind, train_predict, "-") plt.legend() plt.xlabel("Observation number after given time steps") plt.ylabel("Bikeshare Users Scaled") plt.title("Actual and Predicted Values") plt.show()plot_result(trainY, testY, train_predict, test_predict)
2023-04-28 09:25:48.756911: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Each of the three deep learning frameworks performed well to predict daily capital bikeshare ridership. The best performing model was the LSTM model with a test RMSE of 0.1029. The RNN model has a test RMSE of 0.1058 and the GRU model has a test RMSE of 0.1079. This all indicates strong predictive power of each model. Including regularization as a part of the model was key to avoid overfitting to the training data and retain a low test RMSE. The model performs well predicting ridership 1 month in the future.
Deep Learning vs Traditional Model Comparison
Each of the deep learning methods (RNN, LSTM, GRU) drastically outperformed all of the traditional time series methods such as ARIMA and SARIMA. Of the traditional time series methods, SARIMA was the best model which makes sense due to the seasonality of the time series. Even using the SARIMA model, the model just wasn’t able to accurately account for the varaince in the time series data which led to large confidence bounds and generic future predictions. The predictions of the SARIMA model were not much better than what a human would estimate given the previous trend and seasonality of the data. The LSTM model on the other hand, which performed the best of all deep learning models, did a much better job accounting for small variations in the data and therefore more closely fitting the data. This led to a far higher predictive ability. The downside of using these deep learning models is that we lose a lot of the interpretability of why the model made these predictions. In the case of predicting bikeshare usership this we are willing to overlook this because the performance of the deep learning model is so much better.