Capital Bikeshare is operated by LYFT, a popular ridesharing company. While their main business is ridesharing and not bikesharing they do provide bikesharing services for many large cities in the US in addition to electric scooters. Without their investment into bikesharing it would be difficult for these cities to provide this service to its residents. Therefore, I found it of interest to attempt to model the volatility clustering of their stock returns to get a better understanding of their financials.
Code
# Set the start and end dates for the time period you want to analyzestart_date <-"2018-01-01"end_date <-"2023-04-04"# Download the Lyft stock datagetSymbols("LYFT", src ="yahoo", from = start_date, to = end_date)
[1] "LYFT"
Code
# Calculate the daily returnslyft_returns <-dailyReturn(LYFT)# Print the first few rows of the daily returns datahead(lyft_returns)
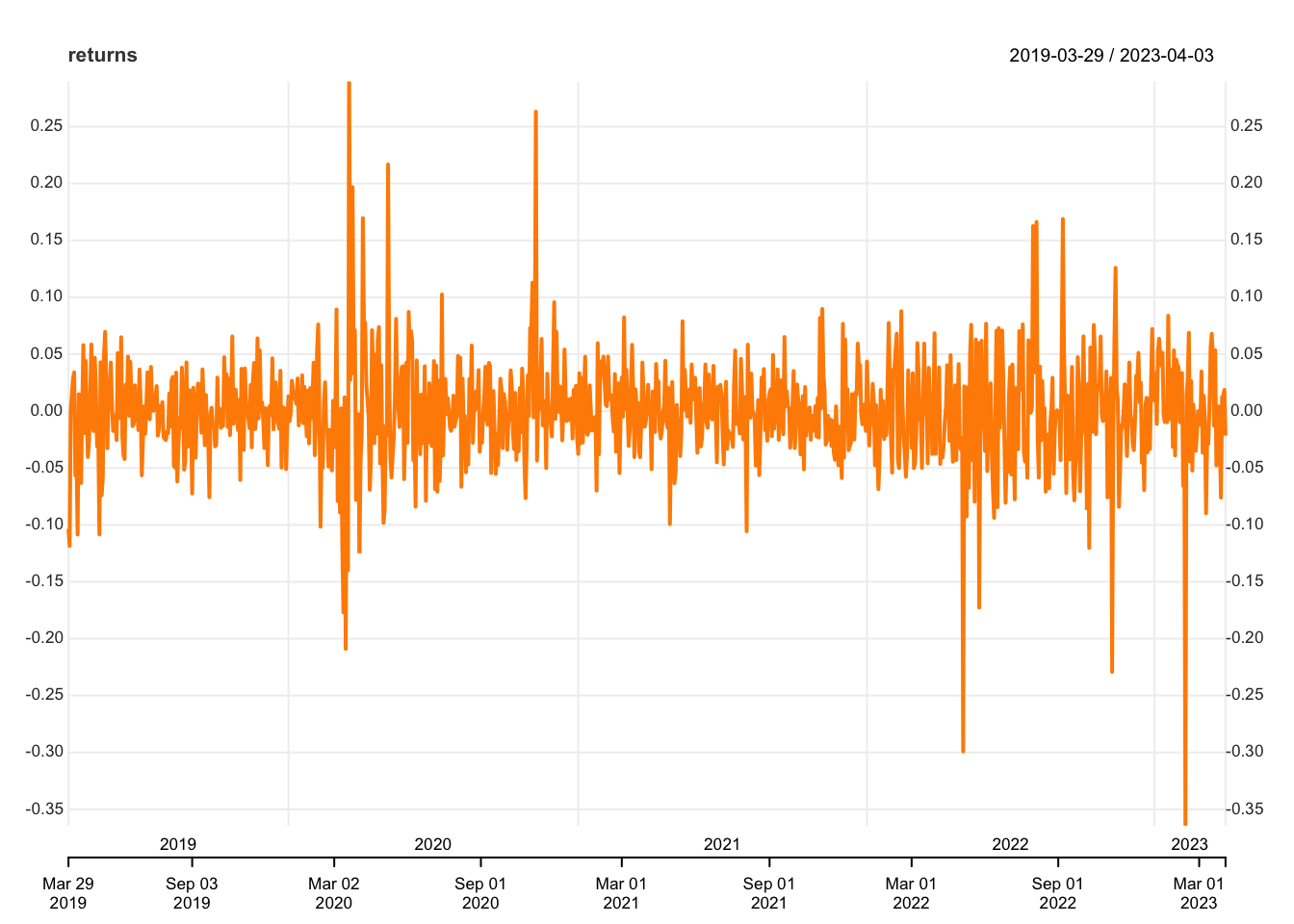
The Daily Returns plots shows clear volatility clustering. There are multiple periods in the time frame where there is a high volalitly period followed by lower volatility. This makes this series a good candidate for arch/garch modelling.
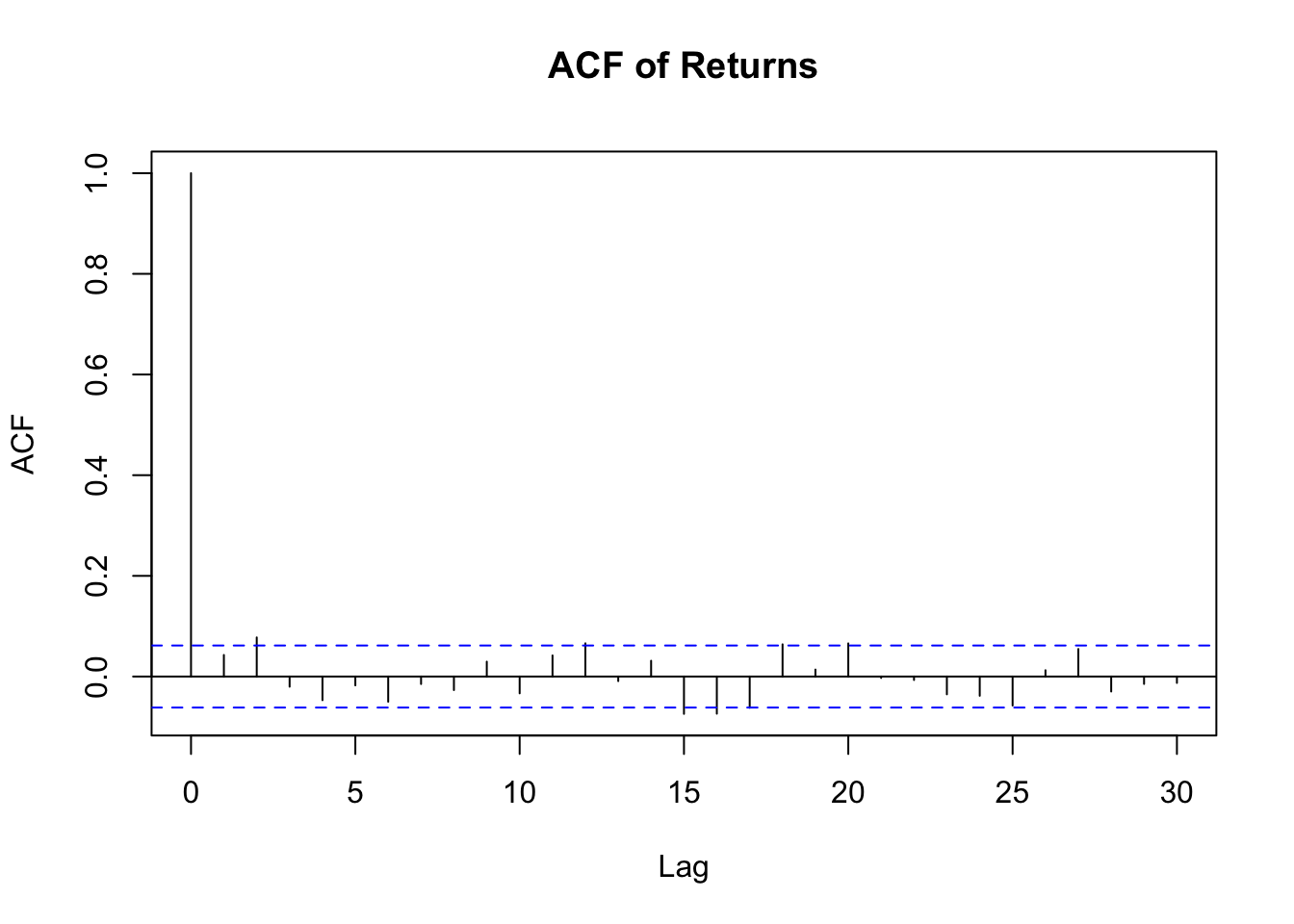
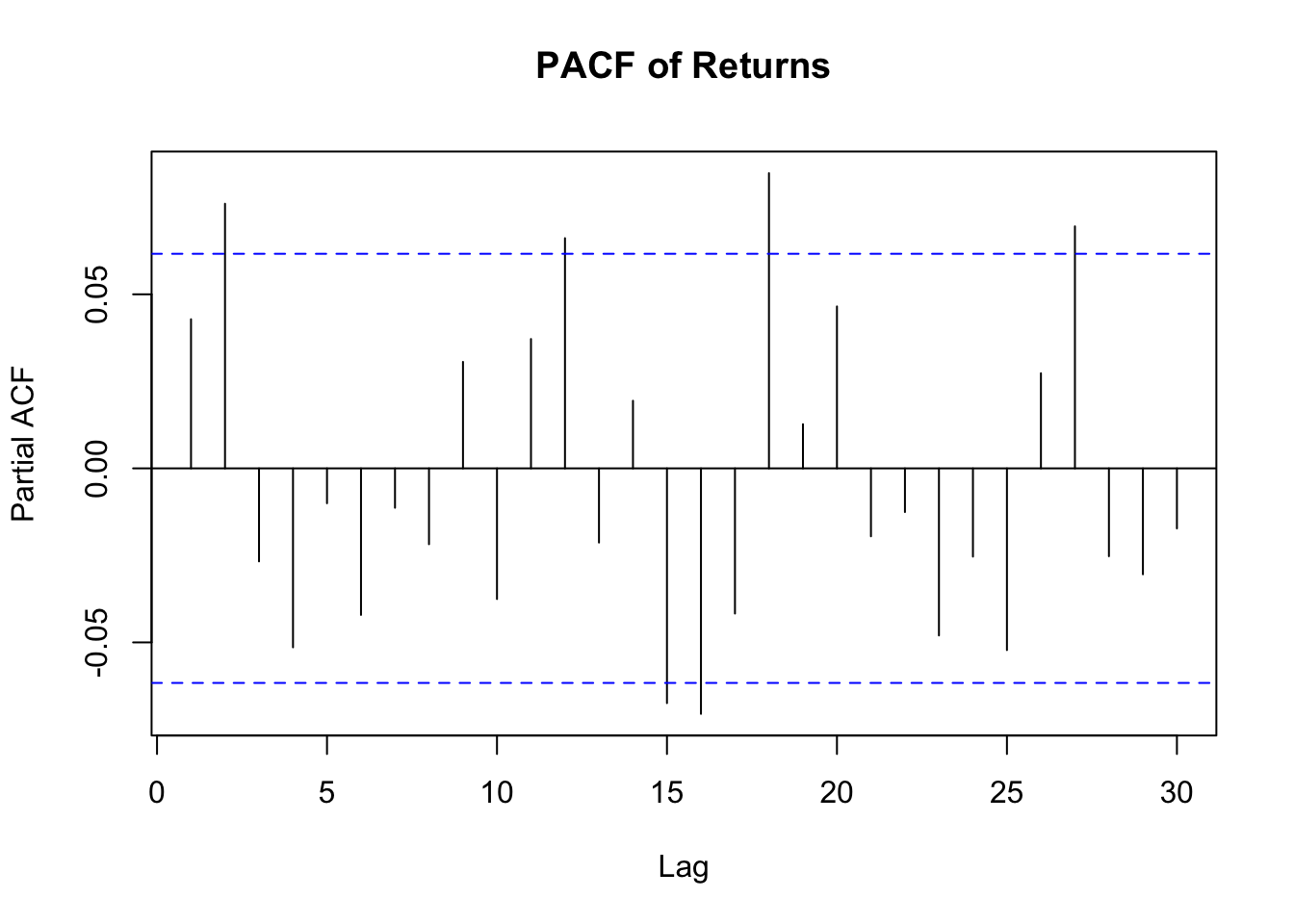
The acf and pacf of the reutrns data both show significant correlation at the first few lags indicating that an arma model is likely suitable for this data. The series doesn’t appear to need differencing but we will check if ARIMA models perform better as well.
Code
acf(returns, main ="ACF of Returns")
Code
pacf(returns, main ="PACF of Returns")
Optimal ARIMA Model
By comparing different values of p,d,q the optimal model based on AIC was found to be an arma(3,3).
Code
optimal_arima <-function(data, max.p, max.d, max.q) {# data: a vector or time series object of your data# max.p: the maximum order of the autoregressive (AR) term# max.d: the maximum order of differencing# max.q: the maximum order of the moving average (MA) term# Create a dataframe to store the results results <-data.frame(p =integer(), d =integer(), q =integer(), AIC =double(), BIC =double())# Calculate the AIC and BIC for each ARIMA(p,d,q) model with p <= max.p, d <= max.d, and q <= max.qfor (i in0:max.p) {for (j in0:max.d) {for (k in0:max.q) {if (i ==0&& j ==0&& k ==0) {next }if (i + j + k >8) {next } model <-Arima(data, order =c(i, j, k)) aic <-AIC(model) bic <-BIC(model) results <-rbind(results, data.frame(p = i, d = j, q = k, AIC = aic, BIC = bic)) } } }# Return the results dataframereturn(results)}results =optimal_arima(returns, 5,3,5)results[which.min(results$AIC),]
p d q AIC BIC
71 3 0 3 -3375.366 -3336.016
Optimal Model Diagnostics
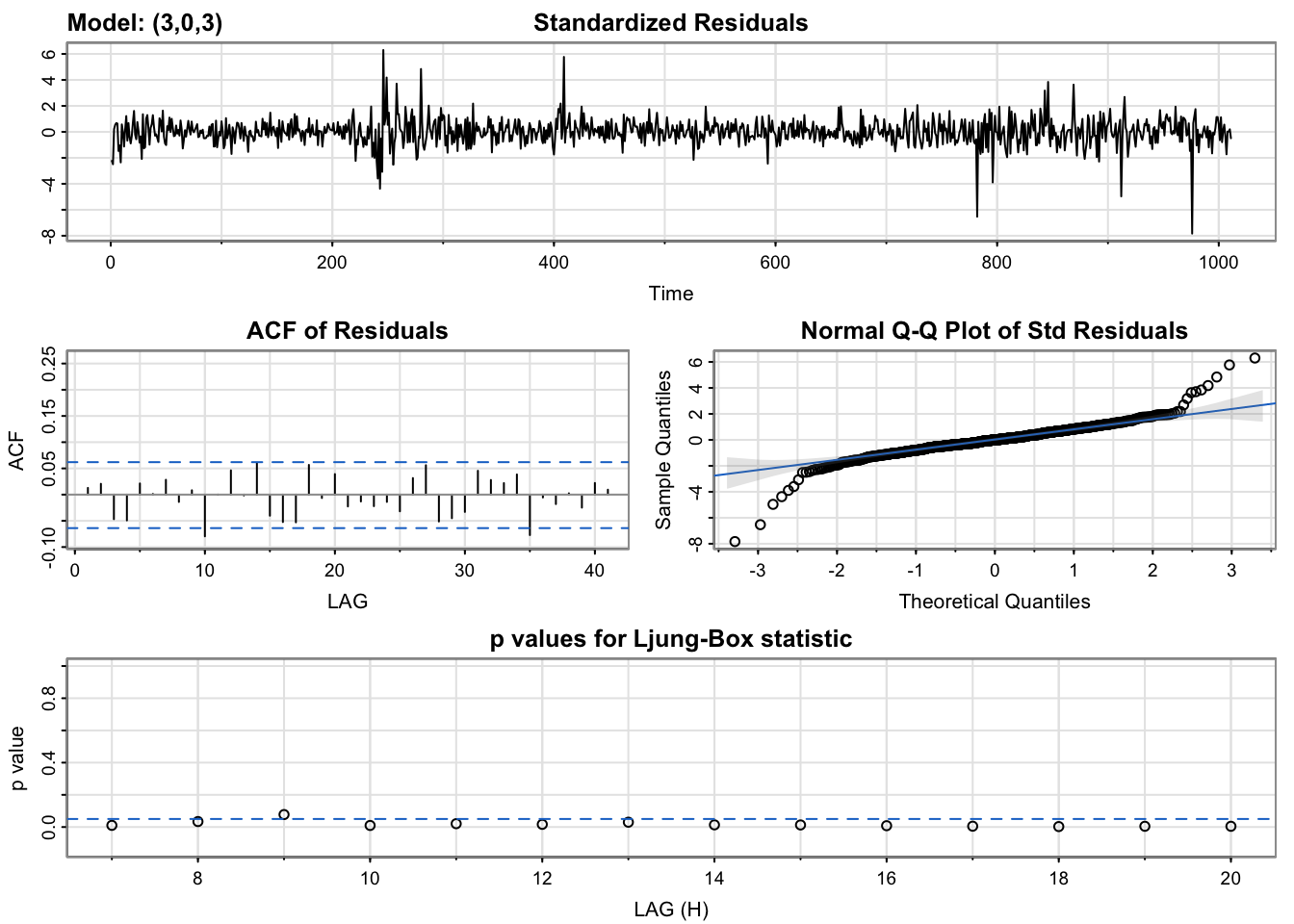
The diagnostics for this model are not great, still showing significant autocorrelation.
Code
fit =Arima(returns, order =c(3,0,3))summary(fit)
Series: returns
ARIMA(3,0,3) with non-zero mean
Coefficients:
ar1 ar2 ar3 ma1 ma2 ma3 mean
0.8664 -0.0034 -0.6061 -0.8523 0.0454 0.5924 -0.0012
s.e. 0.4229 0.6271 0.3986 0.4353 0.6351 0.4148 0.0015
sigma^2 = 0.002058: log likelihood = 1695.68
AIC=-3375.37 AICc=-3375.22 BIC=-3336.02
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 2.197294e-05 0.04521095 0.03146807 Inf Inf 0.6945023 0.01280739
Code
sarima(returns, 3,0,3)
initial value -3.089163
iter 2 value -3.089626
iter 3 value -3.093328
iter 4 value -3.093348
iter 5 value -3.093377
iter 6 value -3.093539
iter 7 value -3.093697
iter 8 value -3.093833
iter 9 value -3.093892
iter 10 value -3.093911
iter 11 value -3.093936
iter 12 value -3.093984
iter 13 value -3.094011
iter 14 value -3.094024
iter 15 value -3.094034
iter 16 value -3.094060
iter 17 value -3.094071
iter 18 value -3.094083
iter 19 value -3.094096
iter 20 value -3.094131
iter 21 value -3.094173
iter 22 value -3.094216
iter 23 value -3.094245
iter 24 value -3.094264
iter 25 value -3.094306
iter 26 value -3.094367
iter 27 value -3.094428
iter 28 value -3.094455
iter 29 value -3.094462
iter 30 value -3.094472
iter 31 value -3.094524
iter 32 value -3.094544
iter 33 value -3.094549
iter 34 value -3.094559
iter 35 value -3.094567
iter 36 value -3.094651
iter 37 value -3.094754
iter 38 value -3.094874
iter 39 value -3.094927
iter 40 value -3.094960
iter 41 value -3.095024
iter 42 value -3.095085
iter 43 value -3.095128
iter 44 value -3.095143
iter 45 value -3.095150
iter 46 value -3.095163
iter 47 value -3.095169
iter 48 value -3.095171
iter 49 value -3.095175
iter 50 value -3.095195
iter 51 value -3.095209
iter 52 value -3.095219
iter 53 value -3.095223
iter 54 value -3.095225
iter 55 value -3.095229
iter 56 value -3.095233
iter 57 value -3.095236
iter 58 value -3.095237
iter 59 value -3.095239
iter 60 value -3.095243
iter 61 value -3.095249
iter 62 value -3.095252
iter 63 value -3.095253
iter 64 value -3.095254
iter 65 value -3.095254
iter 66 value -3.095254
iter 67 value -3.095255
iter 68 value -3.095255
iter 69 value -3.095255
iter 70 value -3.095255
iter 71 value -3.095256
iter 72 value -3.095257
iter 73 value -3.095258
iter 74 value -3.095258
iter 75 value -3.095258
iter 76 value -3.095258
iter 77 value -3.095258
iter 77 value -3.095258
iter 77 value -3.095258
final value -3.095258
converged
initial value -3.090645
iter 2 value -3.090694
iter 3 value -3.090714
iter 4 value -3.090751
iter 5 value -3.090787
iter 6 value -3.090923
iter 7 value -3.091012
iter 8 value -3.091065
iter 9 value -3.091069
iter 10 value -3.091074
iter 11 value -3.091087
iter 12 value -3.091096
iter 13 value -3.091103
iter 14 value -3.091110
iter 15 value -3.091131
iter 16 value -3.091335
iter 17 value -3.091362
iter 18 value -3.091379
iter 19 value -3.091491
iter 20 value -3.091561
iter 21 value -3.091583
iter 22 value -3.091600
iter 23 value -3.091687
iter 24 value -3.091796
iter 25 value -3.092028
iter 26 value -3.092302
iter 27 value -3.093118
iter 28 value -3.093396
iter 29 value -3.095274
iter 30 value -3.095467
iter 31 value -3.095812
iter 32 value -3.095871
iter 33 value -3.095891
iter 34 value -3.096063
iter 35 value -3.096087
iter 36 value -3.096112
iter 37 value -3.096157
iter 38 value -3.096163
iter 39 value -3.096164
iter 40 value -3.096164
iter 41 value -3.096166
iter 42 value -3.096169
iter 43 value -3.096171
iter 44 value -3.096171
iter 45 value -3.096172
iter 46 value -3.096172
iter 46 value -3.096172
final value -3.096172
converged
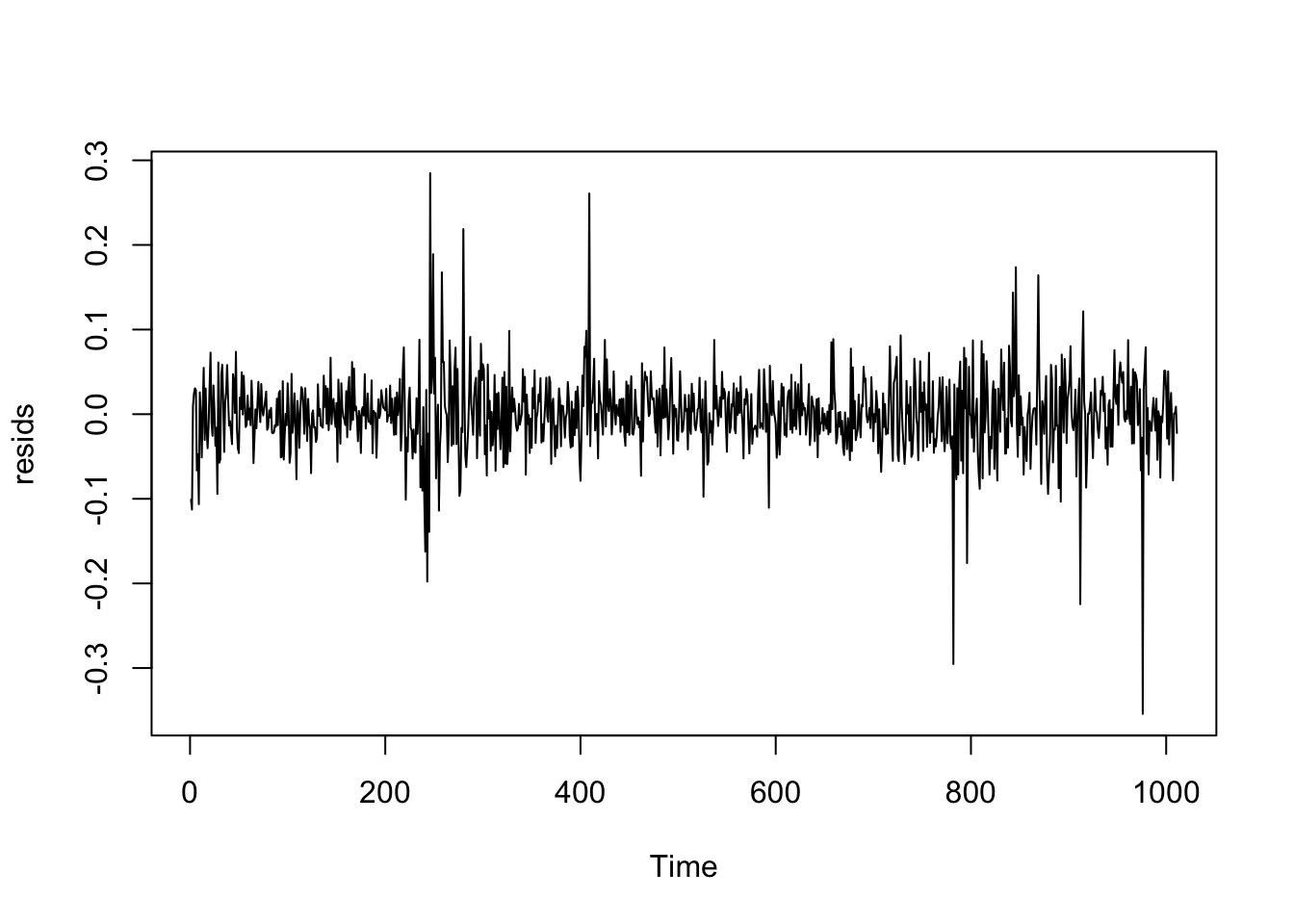
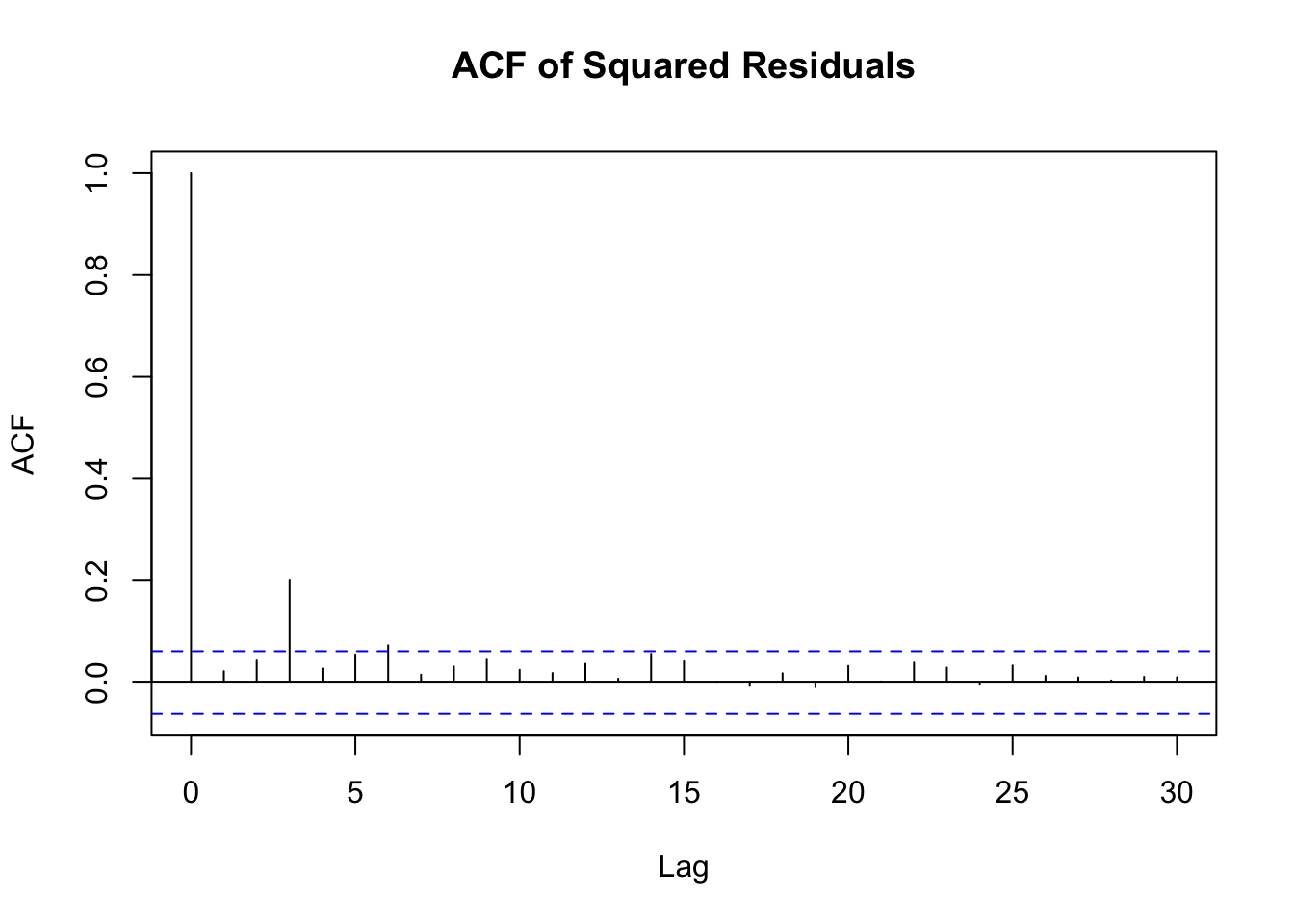
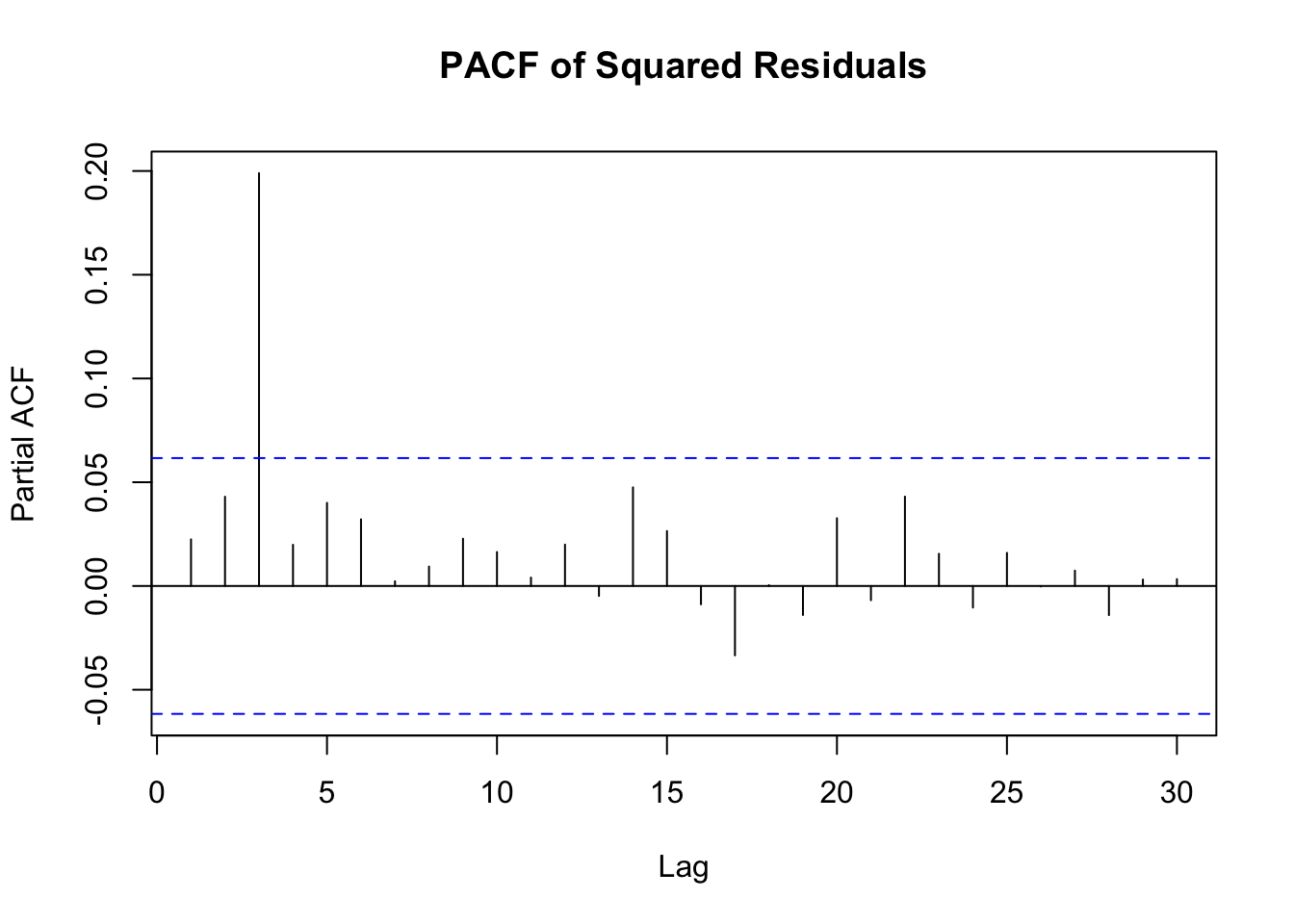
The standardized residuals plot shows that there is still significant volatility not yet modelled by the arma model. The acf and pacf plots of squared residuals both have significant correlation at the first few lags indicating that a garch model would be a good fit for the data. In addition the Arch Test has a p-value less than 0.05 so we can conclude that there are arch affects in the residuals.
Garch Model of (3,1) has the lowest AIC, however after looking at the significance of the coefficients of the model I determined that a GARCH(1,1) is the best model to fit this series. The Ljung-Box Test p-values are all above 0.05 indicating that there is no significant autocorrelation at various lags which is a sign of a good model.
Code
model <-list() ## set countercc <-1for (p in1:7) {for (q in1:7) {model[[cc]] <-garch(resids,order=c(q,p),trace=F)cc <- cc +1}} ## get AIC values for model evaluationGARCH_AIC <-sapply(model, AIC) ## model with lowest AIC is the bestwhich(GARCH_AIC ==min(GARCH_AIC))
The GARCH(1,1) model was the best fit for this data. It performs well on the Ljung-Box Test and does not have significant autocorrelation at any of the lags. The model still has high variation, indicating the need for more data. LYFT stock has only been publicly traded since March 2019, which is only a small dataset. Once LYFT has been traded for longer this analysis will be better able to forecast variation in the returns of its stock price.